
GPU چیست؟ و چه تفاوتی با CPU دارد؟
GPU مخفف Graphics Processing Unit و به معنای واحد پردازش گرافیکی می باشد. مسئولیت اصلی این واحد در گذشته تضمین نمایش محتویات روی صفحه نمایش بوده است. ...
GPU مخفف Graphics Processing Unit و به معنای واحد پردازش گرافیکی می باشد. مسئولیت اصلی این واحد در گذشته تضمین نمایش محتویات روی صفحه نمایش بوده است. ...
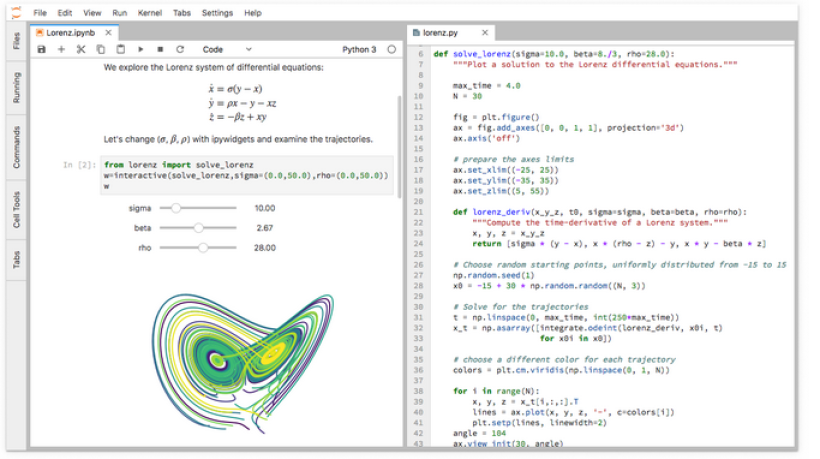
مفتخریم به اطلاع شما برسانیم که در حال حاضر ژوپیتر لب در دسترس کاربران قرار گرفته است، رابط کاربری مبتنی بر وب نسل بعدی ژوپیتر لب برای استفاده روزان ...

یکی از راههایی که هر فرد علاقهمند به فناوری که میخواهد کار خود را در حوزه علم داده آغاز کند برای کسب اطلاعات در پیش میگیرد، جستجوی اینتر ...

به نظر میرسد در یادگیری عمیق همه استفاده از GPU را پیشنهاد میکنند، اما GPU چیست؟ میتوان بدون آن یادگیری عمیق انجام داد؟ و اینکه دقیقا به درد چه کس ...

ژوپیترنوتبوکها یکی از مهمترین محیطهای توسعه پایتون و از محبوبترین ابزارها درزمینهٔ دادهکاوی یا یادگیری ماشین (یادگیری عمیق)هستند.

اخیراً ، من روی نسخه ی دمو محاسبات پیشرفتهای کار می کردم که از یادگیری ماشینی برای تشخیص ناهنجاری ها در سایت یک کارخانه مورد استفاده قرار میگرفت. ا ...

مرور کلی JupyterLab یک محیط کدنویسی فوق العاده برای انجام کارهای مربوط به علم داده میباشد.این 10 دلیل افراد را قانع میکند که برای کدنویسی علم ...

GeForce RTX 3090 GeForce RTX 3090 یک کارت گرافیک پیشرفته مبتنی بر معماری Ampere است. این کارت گرافیک در بردارنده معمار نسل دوم RTX است که عملکرد برای ...