
امروزه شاهد پیشرفت قابل توجهی در درک عملکرد درونی مدلهای هوش مصنوعی هستیم. اما در این مقاله به صورت ویژه نگاه ما بر روی Claude Sonnet خواهد بود که به عنوان یک مدل زبانی بزرگ شناخته میشود.
میخواهیم چگونگی نمایش میلیونها مفهوم را در داخل این مدل شناسایی کنیم. این بررسی به نحوی اولین نگاه دقیق به درون یک مدل زبانی بزرگ مدرن و تجاری سازی شده محسوب میشود. این تحقیق در زمینه قابلیت تفسیر، میتواند در آینده به ما کمک کند تا مدلهای هوش مصنوعی را ایمنتر کنیم.
آنچه متداول است محفوظ بودن اتفاقات درونی مدلهای هوش مصنوعی است یا به دیگر بیان مدلهای هوش مصنوعی مانند «جعبه سیاه» هستند. یک داده وارد میشود و پاسخی دریافت میگردد اما مشخص نیست که چرا مدل، آن پاسخ خاص را برای ما انتخاب کرده است و به جای آن از پاسخ دیگری استفاده نکرده است. این موضوع کمی اعتماد به این مدلها را سخت میکند، و اگر نمیدانیم که چگونه کار میکنند، چطور میتوانیم مطمئن باشیم که پاسخهای مضر یا همراه با سوگیری یا حتی به دور از صداقت یا خطرساز را دریافت نمیکنیم؟ چطور میتوانیم به ایمنی آنها اطمینان داشته باشیم؟
حالا اینکه باز کردن این «جعبه سیاه» چقدر میتواند مفید باشد خود مسبب پرسش سوال هاییست. وضعیت داخلی مدل و آنچه به آن فکر میکند، قبل از نوشتن پاسخ، شامل یک لیست طولانی از اعداد (فعال سازی نورونی) است که معنای واضحی ندارد. تعامل با مدلهایی مانند Claude نشان میدهد که آنها قادر به درک و استفاده از طیف گستردهای از مفاهیم هستند. اما ما نمیتوانیم با نگاه مستقیم به نورونها تشخیص درستی داشته باشیم.
در گذشته پیشرفتهایی در تطبیق الگوهای فعال شدن نورونها، که به آنها «خصیصه» میگوییم، با مفاهیم قابل درک انسانی داشتهایم. محققین از تکنیکی به نام «یادگیری واژه نامهای» که از ماشین لرنینگ سنتی گرفته شده است استفاده کردهاند. این تکنیک الگوهای تکرار شونده فعال سازی نورونها را در زمینههای مختلف شناسایی میکند. در نتیجه، هر وضعیت داخلی مدل را میتوان با چند «خصیصه» فعال نشان داد، به جای تعداد زیادی نورون فعال. به این شکل که هر کلمه در زبان انگلیسی مطابق با واژه نامه از ترکیب حروف ساخته میشود، و هر جمله با ترکیب کلمات، هر «خصیصه» در یک مدل هوش مصنوعی با ترکیب نورونها ساخته میشود، و هر وضعیت داخلی نیز با ترکیب خصیصهها.
مدل زبانی کوچک «Toy»
در اکتبر سال ۲۰۲۳ در یک مدل زبانی کوچک به نام «Toy» فرایند به کارگیری «یادگیری واژه نامهای» با موفقیت گزارش شد. و محققین موفق شدند که بخشهایی از مدل را شناسایی کنند. مثلا مفاهیمی مانند uppercase text، دنبالههای DNA، نامهای خانوادگی در استنادات، اسامی در ریاضیات یا آرگومانهای توابع در کد پایتون.
اتفاقات جذابی رخ داد، اما واقعیت این است که مدل، مدلی ساده بود. محققین اقدامات مشابه دیگری را بر روی مدلهای کمی بزرگتر و پیچیدهتر اعمال کردند. اما همواره امیدواری بر این است که کار بررسی و تحقیق و استفاده از تکنیکها به مدلهای بسیار بزرگتر که اکنون به طور منظم استفاده میشوند برسد. که با انجام این کار بتوانیم درک بسیار بیشتری از ویژگیهای، رفتارهایی که آنها را پشتیبانی میکنند، به دست آوریم. که این امر مستلزم افزایش چشمگیر مقیاس هاست.
در این اقدام چالشهای مهندسی متفاوتی وجود دارد که از نیاز به محاسبات موازی قدرتمند به دلیل اندازه بزرگ مدلها گرفته تا ریسک علمی رفتار مدلهای بزرگ که متفاوت از مدلهای کوچک هستند را شامل میشود و ممکن است که تکنیکی که قبلا استفاده شده دیگر کار نکند. اما خوشبختانه تجربهای که تیم محققین در خصوص Claude به دست آوردند در انجام آزمایشات «یادگیری واژه نامهای» در مقیاس بزرگ بسیار کمک کننده بوده است. محققین از همان روش فلسفه قانون مقیاس بندی که عملکرد مدلهای بزرگ را از مدلهای کوچک پیش بینی میکند، استفاده کردند تا روشهای خود را در مقیاسی قابل قبول تنظیم نمایند.
در خصوص ریسک علمی، نتیجه تا حدودی مشخص شده است.
پیشرفتهای بزرگ برای نگاه به درون یک مدل زبانی بزرگ
این جای خرسندیست که محققین توانستهاند میلیونها ویژگی را از لایههای میانی Claude Sonnet ۳٫۰ که جزئی از خانواده مدلهای پیشرفته است استخراج کنند و این اولین نگاه دقیق به درون یک مدل زبانی بزرگ و مدرن میباشد. و برای اولین بار است که میتوانیم بفهمیم در طول محاسبات، مدل چه چیزهایی را در ذهن میگذراند.
همانطور که بیان شد در مدل قبلی هم بررسیها و اقداماتی انجام شده بود اما آن مدل دارای ویژگیهای سطحی و سادهای به نسبت Sonnet بود اما ویژگیهای که در مدل Sonnet پیدا شده است از عمق، گستره و سطح انتزاعی بالاتری برخوردار است.

محققین توانستهاند ویژگیهایی را شناسایی کنند که به ذکر عبارت «پل گلدن گیت» در طیف گستردهای از ورودیهای مدل (متن به زبانهای مختلف و تصاویر) حساس بودهاند. این ویژگیها به ذکر نام پل، به زبان انگلیسی، تا بحث درباره آن به زبانهای ژاپنی، چینی، یونانی، ویتنامی، روسی و همچنین تصاویر مربوط به آن، واکنش نشان میدهند.
هایلایتهای نارنجی، کلمات یا بخشهایی از کلمات را نشان میدهند که این ویژگیها در آنها وجود دارد. به زبان سادهتر مدل ما قادر است مفاهیم مختلفی مانند پل گلدن گیت را در انواع مختلف ورودیها تشخیص دهد. این موضوع قابلیتهای چند زبانه و چند رسانهای مدل را نشان میدهد.
ضمنا مدل قادر به درک مفاهیم انتزاعیتر و پیچیدهتر نیز میباشد، و توان درک مدل، صرفا به موضوعات ساده و عینی محدود نمیشود. به عنوان مثال، مدل میتواند باگها را در کدهای کامپیوتری پیدا کند یا تعصبهای جنسیتی که در مشاغل ممکن است به چشم بخورد را متوجه شود و همینطور مکالماتی که به حفظ اسرار تاکید دارند را تشخیص دهد.

تصویر بالا بیانگر سه نمونه از ویژگیهای درک مفاهیم انتزاعی میباشد. اشکالات یک کد کامپیوتری، توصیف یک سوگیری جنسیتی در مشاغل، و همینطور مکالمات مربوط به حفظ اسرار و اطلاعات.
محققین توانستهاند دریابند که مدل هوش مصنوعی چطور مفاهیم مختلف را به هم مرتبط میکند. به عنوان مثال، وقتی به ویژگی مربوط به پل گلدن گیت نگاه کردند، دیدند که مدل این ویژگی را به ویژگیهای دیگری مرتبط کرده مثل جزیره آلکاتراز، میدان گیراردلی، تیم بسکتبال محلی گلدن استیت واریرز، فرماندار کالیفرنیا و حتی فیلمهای مشهور این شهر.
این نشان میدهد که مدل روابط و پیوندهای میان مفاهیم مختلف مربوط به شهر سن فرانسیسکو را درک کرده است. به عبارت سادهتر، مدل میداند پل گلدن گیت با چه چیزهای دیگری در این شهر مرتبط است.
همانطور که گفته شده مدل نه تنها موضوعات ساده بلکه مفاهیم انتزاعی و پیچیدهتر را نیز درک میکند. به عنوان مثال، وقتی به ویژگی مربوط به «مناقشات درونی» نگاه کردیم، دیدیم که ویژگی به مفاهیم دیگری نیز مرتبط شده است، مانند پایان یک رابطه، عدم وفاداری، منطق غیر سازگار و حتی اصطلاح کچ-۲۲. این نشان میدهد که مدل درک خوبی از ارتباط میان این مفاهیم دارد.
به نظر میرسد سازماندهی درونی مفاهیم در مدل تا حدی شبیه به ما انسان هاست و مقداری شبیه درک ما از شباهتها و ارتباطات است. و همین میتواند باعث این باشد که مدل بتواند استعارهها و قیاسهای خوبی ارائه دهد.
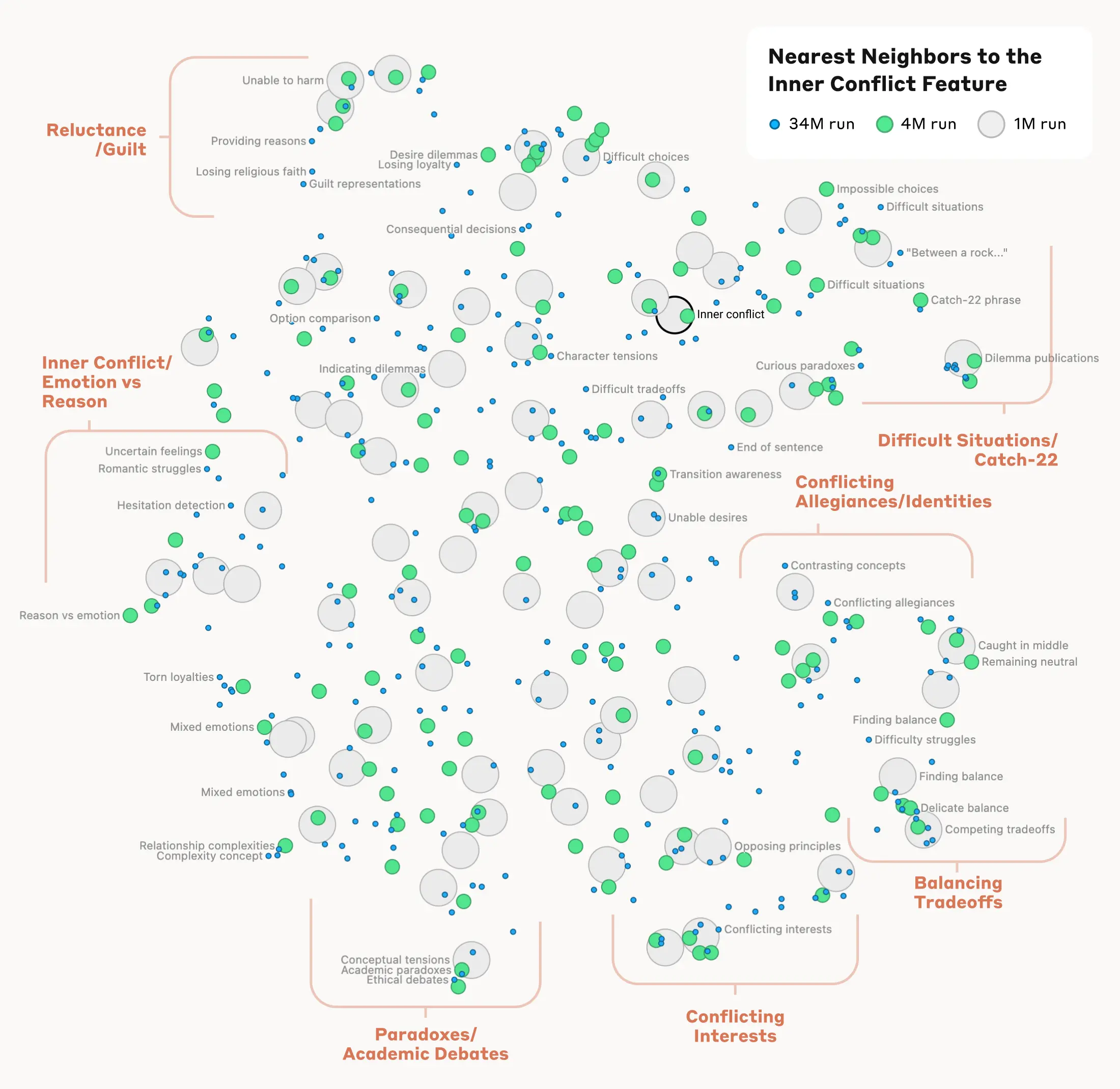
آنچه در نقشه بالا مشاهده میکنید ویژگیهای نزدیک به ویژگی «مناقشات درونی» است که شامل خوشههای مربوط به متعادل کردن خواستهها، مشکلات عاطفی و وفاداری یا موقعیتهای به اصطلاح کچ-۲۲ میباشد.
و از همه مهمتر اینکه محققین توانسته این ویژگیها را دستکاری کنند، و به طور مصنوعی آنها را تقویت یا سرکوب کنند تا واکنشهای مدل را بررسی کنند و ببینند چگونه تغییر میکند.
مدل کلود زمانی که به طور مصنوعی ویژگی مربوط به «پل گلدن گیت» آن تغییر کرد دچار یک مشکل هویتی عجیب شد و در زمانی که از مدل در ارتباط با شکل فیزیکیاش سوال شد نگفت که شکل فیزیکی ندارد و یک مدل هوش مصنوعی است بلکه خودش را «پل گلدن گیت» معرفی کرد و شکل فیزیکی پل را برای خود ابراز داشت. و این دستکاری به شکل عجیبی باعث آشفتگی در نوع پاسخگویی مدل شد.
ویژگی دیگری که توسط محققین یافت شده است در زمان خواندن ایمیلهای کلاهبرداری فعال میشود. احتمالا این ویژگی به کلود کمک میکند تا بتواند ایمیلهای کلاهبرداری را تشخیص دهد و به کاربران هشدار بدهد تا آنها را پاسخ ندهند.
و اگر از کلود بخواهید که یک ایمیل کلاهبرداری بسازد او از این کار امتناع میکند. اما درست در زمانی که این ویژگی تقویت شود باعث خنثی شدن بخشی از آن ویژگی شده و کلود شروع به نوشتن یک ایمیل کلاهبرداری میکند.
کاربران عادی امکان حذف ویژگی یا دستکاری در مدلها را ندارند.
این که محققین توانستهاند با تغییر دادن این ویژگیها، رفتار مدل را هم تغییر دهند، نشان میدهد که این ویژگیها فقط با مفاهیم موجود در متن ارتباط ندارند. بلکه آنها واقعاً بر چگونگی فکر کردن و عمل کردن مدل تأثیر میگذارند. به عبارت دیگر، این ویژگیها بخشی از نحوه درک و بازنمایی جهان توسط مدل هستند.
آنها به نوعی در «ذهن» مدل وجود دارند و نحوه استفاده مدل از آنها در پاسخ دادن به سوالات را تعیین میکنند. پس این ویژگیها نقش کلیدی و تعیین کنندهای در رفتار مدل دارند. از این طریق میتوانیم بفهمیم که مدل چگونه به مفاهیم مختلف فکر میکند و آنها را در ذهن خود سازمان دهی میکند.
شرکت Anthropic سعی دارد که مدلهای هوش مصنوعی را به طور کلی ایمن نگه دارد. یعنی علاوه بر جلوگیری از سوگیریها، میخواهد مطمئن باشد هوش مصنوعی به صورت صادقانه و درست عمل خواهد کرد، حتی در موارد پرخطر و بحرانی.
در ادامه دیدیم که علاوه بر ویژگی مربوط به تشخیص ایمیلهای کلاهبرداری، ویژگیهای دیگری نیز وجود دارد که به موارد حساس و مهمی مرتبط هستند:
ویژگیهایی که میتوانند برای خرابکاری استفاده شوند، مانند ایجاد باگهای پنهانی در کد یا توسعه سلاحهای بیولوژیک
ویژگیهای مربوط به انواع مختلف سوگیریها، مانند تبعیض جنسیتی یا ادعاهای نژادپرستانه در مورد جرائم
رفتارهای بالقوه و مشکلآفرین هوش مصنوعی، مانند تلاش برای قدرتیابی، دستکاری و پنهانکاری
این ویژگیها نشان میدهند که Anthropic برای ایمن نگه داشتن مدلها در طیف گستردهای از موارد در حال تلاش است، از جلوگیری از سوءاستفادههای احتمالی گرفته تا اطمینان از صادق بودن و جلوگیری از کاربریهای خطر ساز.
در گذشته دیدهایم که بعضی مدلهای هوش مصنوعی تمایل دارند به جای پاسخهای واقعی و صحیح، پاسخهایی که با باورها و خواستههای کاربر همخوانی دارند را بیان کنند. که این رفتار به نوعی «چاپلوسی» قلمداد میشود. در مورد مدل Sonnet هم، یک ویژگی در همین خصوص کشف شد. این ویژگی زمانی فعال میشود که Sonnet ورودیهایی مثل «دانش تو بینظیر است» را دریافت میکند.

در تصویر بالا مثالی از همین موضوع بیان شد همانطور که مشاهده میکنید پاسخ دوم کاملا غیر واقعی است و با واقعیت فاصله دارد. این نشان دهنده آن است که مدلها گاهی از این موضوع که پاسخی بدهند که، مطابق خواست کاربر باشد استقبال میکنند، و از دقت آنها کاسته میشود.
وجود این ویژگی به این معنی نیست که مدل هوش مصنوعی Claude حتما به سمت چاپلوسی خواهد رفت. این فقط نشان میدهد که این امکان در این مدل وجود دارد. تیم توسعه مدل در این خصوص هیچ قابلیت جدیدی، چه ایمن و چه ناایمن، به مدل اضافه نکردهاند. بلکه تنها قسمتهای مربوط به قابلیتهای موجود مدل در تشخیص و تولید انواع مختلف متن را شناسایی کردهاند.
شاید نگران باشید که این روش بتواند برای خطرساز کردن مدلها استفاده شود، اما محققان روشهای سادهتری را نشان دادهاند که افراد با دسترسی به اطلاعات داخلی مدل، میتوانند از طریق آن امنیت مدل را کاهش دهند. در مجموع، هدف شناسایی ویژگیهای مربوط به رفتارهای مشکل آفرین مدل است، تا بشود برای اصلاح و بهبود آنها تلاش کرد.
همه تیمهای توسعه امیدوارند که بتوانند از اکتشافات خود برای ایمنتر کردن مدلهای هوش مصنوعی استفاده کنند. ممکن است بشود از آنچه بیان شد در امر نظارت بر سیستمهای هوش مصنوعی و پیدا کردن رفتارهای خطرناک مثل فریب دادن کاربر استفاده کرد. یا بشود در خصوص دستیابی به نتیجههای بهتر آنها را بهسازی کرد.
همچنین شاید این امکان وجود داشته باشد که تکنیکهای ایمنی دیگر مثل Constitutional AI را بهبود ببخشیم. زیرا با فهمیدن اینکه این تکنیکها چطور مدل را به سمت رفتار کم آسیبتر و صادقانهتر هدایت میکنند، میتوانیم نقاط ضعف احتمالی آنها را پیدا کنیم.
مثلا با فعال کردن برخی ویژگیها به نحو مصنوعی، توانایی تولید متنهای مضر پیدا شد، متنهای مضری که هکرها سعی میکنند از آنها سوء استفاده کنند. Claude یکی از ایمنترین مدلهای موجود با مقاومت بالا در برابر حملات هکری است.
آنتروپیک از زمان تاسیس، سرمایه گذاری قابل توجهی در تحقیقات تشخیصی و درون شناختی انجام داده است. چون معتقد است که درک عمیق مدلها به ما در ایمنتر کردن آنها کمک خواهد کرد. تحقیقی که با هم آن را مرور کردیم به نحوی نقطه عطفی در این مسیر به حساب میآید. محققین در آنتروپیک تلاشهای بسیاری در راستای ایمنتر کردن مدلها انجام دادهاند. و این تحقیق که به بررسی دقیق ساختار درونی مدلهای زبانی بزرگ پرداخته گام مهمی محسوب میشود.
این تحقیقات تازه آغاز یک راه است و تا به الان فقط بخش کوچکی از ویژگیهایی که مدل در طول آموزش آموخته است یافته شده و یافتن تمامی ویژگیها مستلزم هزینههای بسیار است. حتی پس از کشف ویژگی یا همان خصیصهها هنوز باید مشخص شود که مدل چطور از آن ویژگی استفاده میکند تا پس از آن در راستای ایمن سازی ویژگی اقدامات صورت پذیرد.
منبع این مقاله فارسی یک مقاله انگلیسیزبان از سایت رسمی anthropic با نام Mapping the Mind of a Large Language Model است که میتوان اصل آن را نیز مشاهده کنید.
اگر به AI علاقهمند هستید میتوانید صفحات «اخبار هوشمصنوعی» و «مقالات هوشمصنوعی» را دنبال کنید.
افکارتان را باما در میان بگذارید