این مقاله به طور خلاصه به شما خواهد گفت که ترانسفورمر چیست و چه مزایایی نسبت به مدلهای قبلی دارد. اما قبل از مطالعه کامل مقاله پیشنهاد ما این است که در حدود یک دقیقه و شاید کمتر وقت خود را برای شناخت ابتدایی آنچه پیش رو است صرف نمایید. تلاش شده تا به اختصار و در چند خط مجموعهای از نکات به طور فشرده بیان شود.
قبل از هر چیز باید گفت ترانسفورمر یک مدل یادگیری ماشین «machine learning model» است که برای انجام وظایف پردازش زبان طبیعی به کار میرود. این مدل به جای استفاده از شبکههای عصبی تکراری مانند «LSTM – Long Short-Term Memory»، صرفاً از مکانیزم توجه «attention mechanism» استفاده میکند.
مدل ترانسفورمر شامل دو بخش اصلی است: «encoder» و «decoder». که «encoder» ورودی را به یک بردار چند بعدی تبدیل میکند و «decoder» از این بردار برای تولید خروجی استفاده میکند.
مکانیزم توجه به مدل ترانسفورمر این امکان را میدهد که در هر مرحله از پردازش، به قسمتهای مختلف ورودی توجه کند و وزنهای متفاوتی به آنها اختصاص دهد. این باعث میشود مدل بتواند بهتر وابستگیهای زمانی در دادهها را درک کند.
مزیت اصلی ترانسفورمر نسبت به مدلهای قبلی این است که از شبکههای عصبی تکراری استفاده نمیکند و فقط بر مبنای مکانیزم توجه ساخته شده است. این موجب افزایش سرعت و کارایی مدل میشود.
یکی از کاربردهای مهم ترانسفورمر در ترجمه ماشینی «machine translation» است. همچنین این مدل در سایر وظایف پردازش زبان طبیعی مانند تشخیص گفتار و تولید متن نیز به کار میرود.
به طور خلاصه اینکه، ترانسفورمر یک مدل پیشرفته و کارآمد برای انجام وظایف پردازش زبان طبیعی است که با استفاده از مکانیزم توجه به جای شبکههای عصبی تکراری، عملکرد بهتری نسبت به مدلهای قبلی دارد.
مقدمهای بر ترانسفورمرها و یادگیری توالی به توالی برای یادگیری ماشین
مدلهای جدید یادگیری عمیق با سرعت در حال معرفی شدن هستند و گاهی اوقات دنبال کردن تمام نوآوریها دشوار است. با این حال، به تازگی ثابت شده است که یک مدل شبکه عصبی خاص برای کارهای رایج پردازش زبان طبیعی «natural language processing» موثر است. این مدل ترانسفورمر «Transformer» نام دارد و از چندین روش و مکانیزم استفاده میکند که در این مقاله به معرفی آنها خواهیم پرداخت.
بخش ۱: یادگیری توالی به توالی «Sequence to Sequence Learning» و توجه «Attention»
یادگیری توالی به توالی
توالی به توالی یا «Seq2Seq» یک شبکه عصبی است که یک توالی مشخص از عناصر، مانند توالی کلمات در یک جمله، را به توالی دیگری تبدیل میکند. لازم به ذکر است که مدلهای «Seq2Seq» در ترجمه بسیار خوب عمل میکنند، درست همان جایی که توالی کلمات از یک زبان به توالی کلمات متفاوت در زبان دیگر تبدیل میشود. به عبارت دیگر، مدل ترانسفورمر از یک معماری توالی به توالی استفاده میکند که ورودی را به خروجی تبدیل میکند. مدل این امکان را فراهم میآورد که ورودی و خروجی طول متفاوتی داشته باشند، مانند تبدیل یک جمله انگلیسی به ترجمه آن به یک زبان دیگر.
همانطور که گفته شد مدلهای «Seq2Seq» بهطور خاص برای ترجمه مناسب هستند، جایی که توالی کلمات از یک زبان به توالی کلمات متفاوت در زبان دیگر تبدیل میشود. یک گزینه محبوب برای این نوع مدل، مدلهای مبتنی بر حافظه کوتاه-مدت و بلند-مدت «LSTM» است. با دادههای وابسته به توالی، ماژولهای «LSTM» میتوانند معنا را به توالی بدهند در حالی که بخشهایی که مهم (یا بیاهمیت) میدانند را بهخاطر میسپارند (یا فراموش میکنند). به عنوان مثال، جملات وابسته به توالی هستند زیرا ترتیب کلمات برای درک جمله حیاتی است. «LSTM» گزینهای طبیعی برای این نوع داده هستند.
مدلهای «Seq2Seq» از یک رمزگذار «Encoder» و یک رمزگشا «Decoder» تشکیل شدهاند. رمزگذار توالی ورودی را میگیرد و آن را به یک فضای با ابعاد بالاتر (بردار n-بعدی) نگاشت میکند. آن بردار انتزاعی به رمزگشا تغذیه میشود که آن را به یک توالی خروجی تبدیل میکند. توالی خروجی میتواند به زبان دیگر، نمادها، یک کپی از ورودی و غیره باشد.
برای درک بهتر، رمزگذار و رمزگشا را مانند مترجمان انسانی تصور کنید که فقط میتوانند دو زبان صحبت کنند. زبان اول آنها زبان مادریشان است که بین هر دو متفاوت است (مثلاً آلمانی و فرانسوی) و زبان دوم آنها یک زبان خیالی است که بین آنها مشترک است. برای ترجمه آلمانی به فرانسوی، رمزگذار جمله آلمانی را به زبان دیگری که میداند، یعنی زبان خیالی، تبدیل میکند. از آنجا که رمزگشا قادر به خواندن آن زبان خیالی است، اکنون میتواند از آن زبان به فرانسوی ترجمه کند. مدل (متشکل از رمزگذار و رمزگشا) میتواند آلمانی را به فرانسوی ترجمه کند!
فرض کنید که در ابتدا، نه رمزگذار و نه رمزگشا در زبان خیالی خیلی روان نیستند. به همین دلیل برای یادگیری آن، ما آنها (مدل) را با تعداد زیادی مثال آموزش میدهیم.
یک انتخاب بسیار ساده برای رمزگذار و رمزگشای مدل «Seq2Seq»، یک «LSTM» واحد برای هر کدام از آنهاست.
احتمالا شما به عنوان خواننده مقاله تا به اینجای کار به دنبال ترانسفورمر هستید، کمی شکیبا باشید زیرا برای فهم بهتر ترانسفورمر نیاز به شناخت برخی پیش نیاز هاست.
اما قبل از هر چیز ما به جزئیات فنی دیگر نیاز داریم تا درک ترانسفورمرها را آسانتر کند:
مکانیزم توجه
بیایید ابتدا کمی با مکانیزم توجه آشنا شویم، مکانیزم توجه به یک توالی ورودی نگاه میکند و در هر مرحله تصمیم میگیرد که کدام بخشهای دیگر توالی مهم هستند. این ممکن است انتزاعی به نظر برسد، اما اجازه دهید با یک مثال ساده توضیح دهم: هنگام خواندن این متن، شما همیشه بر روی کلمهای که میخوانید تمرکز میکنید، اما در عین حال ذهن شما هنوز کلمات کلیدی مهم متن را در حافظه نگه میدارد تا زمینه را فراهم کند.
مکانیسم توجه در هوش مصنوعی به این شکل است:
- – تصور کنید مترجمی داریم که متن را ترجمه میکند.
- – این مترجم علاوه بر ترجمه معمولی، کلمات مهم و کلیدی متن را هم مشخص میکند.
- – این کار به مترجم کمک میکند تا بهتر بفهمد کدام بخشهای متن مهمتر هستند.
- – در سیستمهای کامپیوتری، این کار با دادن «وزن» یا اهمیت بیشتر به بعضی کلمات انجام میشود.
- – بخشی از سیستم (رمزگذار) متن را میخواند و بخش دیگر (رمزگشا) آن را ترجمه میکند.
- – مکانیسم توجه به رمزگشا کمک میکند تا بداند کدام قسمتهای متن مهمتر هستند.
- – این روش باعث میشود ترجمههای ماشینی و سایر وظایف پردازش زبان طبیعی بهتر انجام شوند.
به عبارت دیگر، برای هر ورودی که «LSTM» (رمزگذار) میخواند، مکانیزم توجه چندین ورودی دیگر را همزمان در نظر میگیرد و با اختصاص وزنهای مختلف به آن ورودیها تصمیم میگیرد کدامیک مهم هستند. رمزگشا سپس جمله رمزگذاری شده و وزنهای ارائه شده توسط مکانیزم توجه را به عنوان ورودی دریافت میکند.
بخش ۲: ترانسفورمر
مقاله «Attention Is All You Need» یک معماری جدید به نام ترانسفورمر «Transformer» را معرفی میکند. همانطور که از عنوان پیداست، این معماری از مکانیسم توجه که قبلاً دیدیم استفاده میکند. مانند «LSTM»، ترانسفورمر نیز معماریای برای تبدیل یک توالی به توالی دیگر با کمک دو بخش (رمزگذار و رمزگشا) است، اما با مدلهای توالی به توالی قبلی تفاوت دارد زیرا از هیچ شبکه بازگشتی («GRU»، «LSTM» و غیره) استفاده نمیکند.
تا به حال، شبکههای بازگشتی یکی از بهترین روشها برای درک وابستگیهای زمانی در توالیها بودند. اما در مقاله «Attention Is All You Need»، محققان نشان دادند که میتوان از یک معماری جدید به نام ترانسفورمر «Transformer» استفاده کرد که بر اساس مکانیزم توجه «attention mechanism» کار میکند. این معماری بدون استفاده از شبکههای عصبی تکراری «RNN» میتواند نتایج بهتری در کارهایی مانند ترجمه به دست آورد. همچنین، مقاله «BERT» که معرفی کننده پیشآموزش ترانسفورمرهای دوطرفه عمیق برای درک زبان است، بهینه سازیهایی در وظایف مربوط به زبان طبیعی ارائه داده است. این بدان معنی است که با استفاده از ترانسفورمرها و مکانیزم توجه، میتوان به نتایج بهتری در حوزه پردازش زبان طبیعی دست یافت.
اما سوال اینجاست که ترانسفورمر دقیقاً چیست؟
بیایید از روی تصویر پیش برویم، چرا که هر تصویر میتواند از هزاران کلمه نافذ تر عمل کند.
رمزگذار در سمت چپ و رمزگشا در سمت راست قرار دارد. هر دو از ماژولهایی تشکیل شدهاند که میتوانند چندین بار روی هم قرار گیرند، که با «Nx» در تصویر نشان داده شده است. میبینیم که این ماژولها عمدتاً از لایههای «Multi-Head Attention» و «Feed Forward» تشکیل شدهاند. ورودیها و خروجیها (جملات هدف) ابتدا در یک فضای n-بعدی جاسازی میشوند زیرا نمیتوانیم مستقیماً از رشتهها استفاده کنیم.
یک بخش کوچک اما مهم مدل، کدگذاری موقعیتی کلمات مختلف است. از آنجا که شبکههای بازگشتی نداریم که بتوانند به یاد داشته باشند توالیها چگونه به مدل تغذیه میشوند، باید به نوعی به هر کلمه/بخش در توالیمان یک موقعیت نسبی بدهیم، زیرا یک توالی به ترتیب عناصرش وابسته است. این موقعیتها به نمایش جاسازی شده (بردار n-بعدی) هر کلمه اضافه میشوند.
بیایید نگاه دقیقتری به این بلوکهای «Multi-Head Attention» در مدل بیندازیم
با توضیح سمت چپ مکانیسم توجه شروع کنیم. این مکانیسم چندان پیچیده نیست و میتواند با معادله زیر توصیف شود.
ماتریس «Q» حاوی پرسوجو (بردار نمایش دهنده یک کلمه در توالی) است، «K» همه کلیدها (بردارهای نمایش دهنده همه کلمات در توالی) و «V» مقادیر هستند، که باز هم بردارهای نمایش دهنده همه کلمات در توالی هستند. برای رمزگذار و رمزگشا، ماژولهای توجه چندگانه، «V» شامل همان توالی کلمات «Q» است. با این حال، برای ماژول توجه که توالی رمزگذار و رمزگشا را در نظر میگیرد، «V» متفاوت از توالی نمایش داده شده توسط «Q» است.
به عبارت سادهتر، در معماری ترانسفورمر، سه مفهوم اصلی وجود دارد:
«Q – Query» : این بردار نمایشگر یک کلمه یا عبارت است که قرار است بررسی شود.
«K – Keys»: این بردارها نمایشگر تمام کلمات در ورودی هستند.
«V – Values»: این بردارها هم نمایشگر تمام کلمات در ورودی هستند.
در لایههای رمزگذار و رمزگشا، «V» همان توالی ورودی است، یعنی همان کلماتی که در ورودی هستند.
اما در تعامل بین رمزگذار و رمزگشا، «V» متفاوت است. یعنی مقادیر «V» که رمزگشا استفاده میکند با مقادیری که رمزگذار استفاده میکند، متفاوت است.
برای سادهسازی کمی بیشتر، میتوانیم بگوییم که مقادیر در «V» با برخی وزنهای توجه «a» ضرب و جمع میشوند، که وزنهای ما به این صورت تعریف میشوند.
۱. مکانیزم توجه «Attention Mechanism»:
– تصور کنید شما در حال خواندن یک جمله هستید. وقتی به هر کلمه میرسید، مغز شما به طور ناخودآگاه به کلمات دیگر در جمله هم توجه میکند تا معنای کامل را درک کند.
– در هوش مصنوعی، مکانیزم توجه همین کار را انجام میدهد. برای هر کلمه «Q» ، سیستم به همه کلمات دیگر «K» نگاه میکند و تصمیم میگیرد کدام کلمات مهمتر هستند.
– وزنها «a» نشان میدهند که هر کلمه چقدر اهمیت دارد. این وزنها بین ۰ و ۱ هستند (به خاطر تابع «SoftMax»).
۲. توجه چند سر «Multi-Head Attention»:
- – حالا تصور کنید که شما میتوانید همزمان از چند زاویه مختلف به جمله نگاه کنید.
- – در هوش مصنوعی، این کار با استفاده از چندین مکانیزم توجه موازی انجام میشود.
- – هر «سر» یا «head» یک دیدگاه متفاوت را نشان میدهد.
- – این کار به سیستم اجازه میدهد تا جنبههای مختلف متن را بهتر درک کند.
۳. کاربرد در «Encoder» و «Decoder»:
- -«Encoder» قسمتی است که متن ورودی را پردازش میکند.
- – «Decoder» قسمتی است که خروجی را تولید میکند.
– مکانیزم توجه در هر دو قسمت استفاده میشود، اما با هدفهای متفاوت:
- – در «Encoder» : به کل متن ورودی توجه میکند.
- – در «Decoder» : به بخشی از خروجی که تا کنون تولید شده است و همچنین به خروجی «Encoder» توجه میکند.
۴. شبکه عصبی «Feed-Forward»:
– بعد از مرحله توجه، هر کلمه از یک شبکه عصبی کوچک عبور داده میشود.
– این شبکه برای همه کلمات یکسان بوده و کمک میکند تا مدل اطلاعات بیشتری را از هر کلمه استخراج کند.
– به طور خلاصه، این سیستم مثل یک خواننده بسیار دقیق عمل میکند که نه تنها به هر کلمه توجه میکند، بلکه ارتباط بین کلمات را هم از زوایای مختلف بررسی میکند. این باعث میشود که درک عمیقتری از متن داشته باشد و بتواند متنهای پیچیده را بهتر پردازش کند.
آموزش «Training»
زمانی که میخواهیم یک مدل «Seq2Seq» (مانند مدلهای ترجمه ماشینی) را آموزش دهیم، رویکرد آموزش کمی متفاوت از مسائل طبقه بندی معمولی است. همین موضوع در مورد مدلهای ترانسفورمر نیز صدق میکند.
برای آموزش مدل ترجمه از فرانسه به آلمانی، ما به جفت جملههایی در این دو زبان که ترجمه یکدیگر هستند، نیاز داریم. وقتی این جفت جملهها را در اختیار داشتیم، میتوانیم شروع به آموزش مدل کنیم.
در این فرآیند آموزش، ورودی رمزگذار «Encoder» جمله فرانسوی است و ورودی رمزگشا «Decoder» جمله آلمانی است. اما ورودی رمزگشا را به سمت راست جابجا میکنیم، به این معنی که هر کلمه در ورودی رمزگشا یک کلمه جلوتر از کلمه مربوطه در خروجی مورد انتظار قرار میگیرد.
دلیل این کار این است که نمیخواهیم مدل فقط بتواند جمله آلمانی را کپی کند. در واقع میخواهیم که مدل بتواند با توجه به جمله فرانسوی و تعدادی از کلمات قبلی در جمله آلمانی، کلمه بعدی را پیش بینی کند.
اگر ورودی رمزگشا را جابجا نکنیم، مدل میتواند فقط جمله آلمانی را کپی کند و نیاز به یادگیری روابط پیچیده بین دو زبان نداشته باشد. در نتیجه، با این جابجایی، مدل مجبور میشود که کلمه بعدی را پیش بینی کند، نه صرفا جمله را کپی کند.
همچنین، برای اولین کلمه در ورودی رمزگشا، یک توکن شروع-جمله قرار میدهیم. در انتهای ورودی رمزگشا نیز یک توکن پایان-جمله قرار میدهیم. این توکنها به مدل کمک میکنند که شروع و پایان جمله را تشخیص دهد، که این موضوع در زمان نتیجه گیری «Inference» نیز مفید است.
این رویکرد آموزش در مدلهای «Seq2Seq» و ترانسفورمر مشابه است. در مورد مدلهای ترانسفورمر، علاوه بر جابجایی ورودی رمزگشا، یک پوشش نیز به ورودی رمزگشا اعمال میشود. این پوشش مانع میشود که مدل بتواند اطلاعات آینده را در نظر بگیرد.
این فرآیند ایجاد ورودی صحیح برای رمزگشا، «Teacher-Forcing» نامیده میشود.
توالی هدفی که میخواهیم برای محاسبات هزینه «loss» در نظر بگیریم، صرفاً ورودی رمزگشا (جمله آلمانی) بدون جابجا کردن آن و با قرار دادن یک نشانگر پایان توالی «end-of-sequence token» در انتها است. به عبارت دیگر، برای محاسبه هزینه «loss»، هدف ما همان جمله آلمانی است که قرار است توسط مدل تولید شود، بدون هیچ جابجایی و با افزودن یک نشانگر پایان جمله در انتها.
استنباط «Inference»
استنباط یا استفاده از مدلهای ترانسفورمر برای ترجمه، با مرحله آموزش متفاوت است. بدیهی است، چون در نهایت میخواهیم یک جمله فرانسوی را ترجمه کنیم بدون اینکه جمله آلمانی باقی بماند. روش کار به این صورت است:
۱. ورودی و خروجی اولیه:
- – تمام جمله فرانسوی به عنوان ورودی به بخش «Encoder» داده خواهد شد.
- – برای شروع، یک توکن «شروع جمله» رو به «Decoder» داده خواهد شد.
۲. تولید کلمه به کلمه:
- – مدل اولین کلمه را پیشبینی میکند.
- – این کلمه به ورودی «Decoder» اضافه میشود.
۳. تکرار فرآیند:
- – مجددا جمله فرانسوی و کلمات تولید شده تا آن لحظه به مدل داده میشوند.
- – مدل کلمه بعدی را پیشبینی میکند.
- – این روند تکرار میشود.
۴. پایان ترجمه:
– این کار تا زمانی که مدل یک توکن «پایان جمله» تولید کند ادامه خواهد یافت.
– این توکن نشان دهنده پایان ترجمه است.
نکته مهم این است که برای ترجمه یک جمله، چندین بار از مدل استفاده میشود. هر بار یک کلمه جدید تولید میشود تا کل جمله تکمیل گردد.
به زبان سادهتر، فکر کنید در حال حل یک پازل هستید. شما تصویر کامل (جمله فرانسوی) را دارید و میخواهید یک تصویر جدید (جمله آلمانی) بسازید. هر بار یک قطعه جدید (کلمه) را اضافه میکنید و به تصویر کامل نگاه میکنید تا مطمئن شوید قطعه بعدی کجا باید قرار بگیرد. این کار را ادامه میدهید تا زمانی که پازل تکمیل شود.
بخش ۳: کاربرد «ترانسفورمر برای سریهای زمانی»
ما معماری «Transformer» را مشاهده کردهایم و از طریق منابع علمی و به لطف نویسندگان مقاله «Attention is All you Need» میدانیم که این مدل در وظایف زبانی عملکرد بسیار خوبی دارد. اکنون بیایید «Transformer» را در کاربرد آزمایش کنیم.
به جای ترجمه، بیایید یک پیشبینی سری زمانی برای جریان ساعتی برق الکتریکی در تگزاس را پیادهسازی کنیم که توسط شورای قابلیت اطمینان برق تگزاس «ERCOT» ارائه شده است.
از آنجا که میتوانیم از مدلهای توالی به توالی مبتنی بر «LSTM» برای پیشبینیهای چند مرحلهای استفاده کنیم، بیایید نگاهی به ترانسفورمر و قدرت آن در انجام این پیشبینیها بیندازیم. با این حال، ابتدا باید تغییراتی در معماری ایجاد کنیم زیرا ما با توالی کلمات کار نمیکنیم بلکه با مقادیر سروکار داریم. علاوه بر این، ما یک خودرگرسیون انجام میدهیم و نه یک طبقهبندی کلمات/کاراکترها.
دادهها
دادههای که در اختیار داریم، مقدار بار برق ساعت به ساعت در کل منطقه «ERCOT» را نشان میدهد. از دادههای سالهای ۲۰۰۳ تا ۲۰۱۵ برای آموزش مدل استفاده شد و دادههای سال ۲۰۱۶ برای آزمایش مورد استفاده قرار گرفت.
برای استفاده از این دادهها در مدل پیش بینی، عملیات پیش پردازش زیر را انجام شد:
علاوه بر مقدار بار برق، ویژگیهای دیگری را هم اضافه شد:
- روز هفته (به صورت «one-hot encoding»)
- سال (۲۰۰۳ تا ۲۰۱۵)
- ساعت (۱ تا ۲۴)
این ویژگیها به مدل کمک میکنند تا الگوهای مربوط به زمان را بهتر درک کند.
برای همگرایی بهتر مدل، مقدار بار برق با تقسیم بر ۱۰۰۰ نرمال سازی شد.
در مرحله پیش بینی، از دادههای ۲۴ ساعت گذشته استفاده شد تا مقدار بار برق ۱۲ ساعت آینده را پیش بینی شود. این اندازه پنجره زمانی (۲۴ ساعت گذشته) را میتوان بر اساس نیاز تغییر داد، مثلا به جای ساعات از روزها استفاده کرد.
هدف این است که با استفاده از الگوهای موجود در دادههای گذشته، بتوان مقدار بار برق آینده را با دقت بیشتری پیش بینی کرد.
تغییرات در مدل نسبت به مقاله اصلی
اولین قدم این است که ما نیاز به حذف کردن «embedding» ها داریم، چون ما در ورودی مقادیر عددی داریم. معمولاً یک «embedding» یک عدد صحیح را به یک فضای n بعدی نگاشت میکند. اما در اینجا به جای استفاده از «embedding» ، از یک تبدیل خطی ساده برای تبدیل دادههای ۱۱ بعدی به فضای n بعدی استفاده شد. این شبیه به کاری است که برای نمایش کلمات انجام میشود. همچنین ما نیاز داریم لایه «SoftMax»را از خروجی «Transformer» حذف کنیم، چون خروجی ما مقادیر واقعی هستند، نه احتمالات. بعد از این تغییرات جزئی، آموزش میتواند شروع شود!
از «Teacher-Forcing» برای آموزش استفاده شد. این بدین معنی است که رمزگذار یک پنجره ۲۴ تایی از دادهها را به عنوان ورودی دریافت میکند و ورودی رمزگشا یک پنجره ۱۲ تایی است که اولین آن یک مقدار «start-of-sequence» است و بقیه دنباله هدف هستند. با معرفی یک مقدار «start-of-sequence» در ابتدا، ورودی رمزگشا را نسبت به دنباله هدف جا جابجا شد.
از یک بردار ۱۱ بعدی با مقادیر -۱ به عنوان مقادیر «start-of-sequence» استفاده شد. البته این مقدار قابل تغییر است و شاید استفاده از مقادیر دیگر بسته به مورد استفاده، الزامی باشد، اما برای این مورد همین مقدار کار میکند چون هیچ مقادیر منفی در هیچ یک از ابعاد دنباله ورودی/خروجی نداریم.
تابع هزینه برای این مثال ساده انحراف مربعات میانگین است.
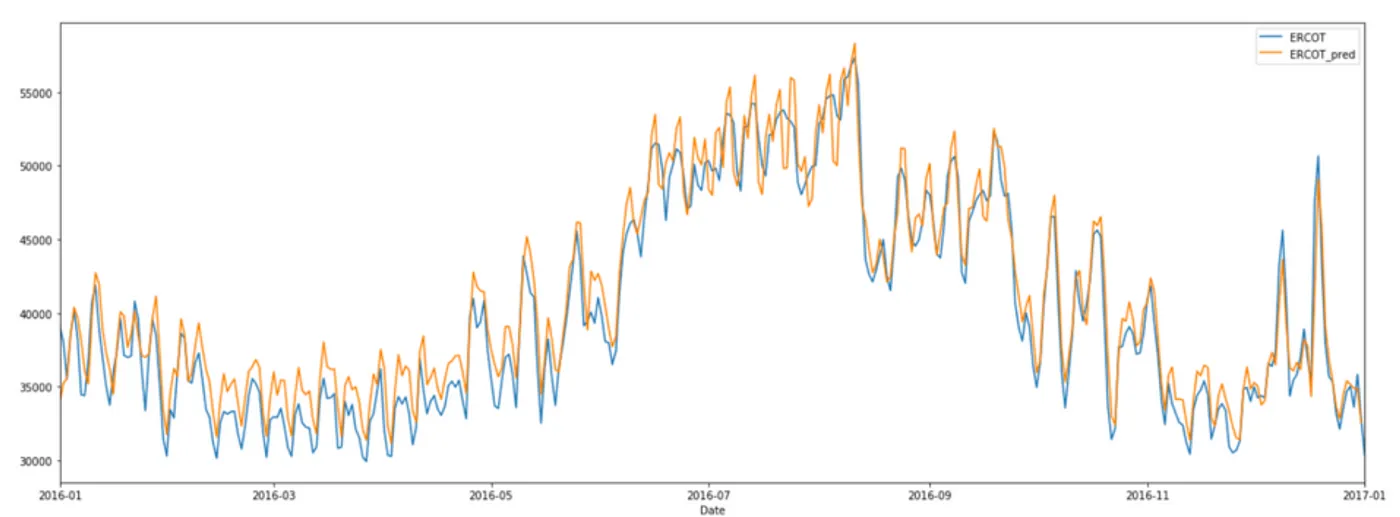
نتایج
دو نمودار زیر نتایج را نشان میدهند.
در نمودار اول، مدل، پیش بینیهای ۱۲ ساعته را با استفاده از ۲۴ ساعت قبلی انجام داده است. این نشان میدهد که مدل تا حد زیادی قادر است نوسانات را درک کند.
در نمودار دوم، مدل، پیش بینی یک ساعته را با استفاده از ۲۴ ساعت قبلی انجام داده است. این هم نشان میدهد که مدل تا حد خوبی قادر به پیش بینی نوسانات است.
در ارزیابی عملکرد مدل، ریشه میانگین مربعات خطا محاسبه شده است. برای مجموعه آموزشی این مقدار ۸۵۹ بوده و برای مجموعه اعتبارسنجی ۴٬۱۰۶ برای پیش بینیهای ۱۲ ساعته و ۲٬۵۸۳ برای پیش بینیهای یک ساعته بوده است.
همچنین میزان خطای درصد مطلق متوسط پیش بینی مدل، محاسبه شده است که ۸٫۴٪ برای نمودار اول (پیش بینی ۱۲ ساعته) و ۵٫۱٪ برای نمودار دوم (پیش بینی ۱ ساعته) است. این نشان میدهد که مدل توانسته است پیش بینیهای نسبتاً دقیقی را ارائه دهد.
خلاصه
نتایج نشان میدهد که استفاده از معماری Transformer برای پیشبینی سریهای زمانی امکانپذیر است. با این حال، در طول ارزیابی مشخص میشود که هر چه بخواهیم گامهای بیشتری را پیشبینی کنیم، میزان خطا افزایش مییابد. نمودار اول با استفاده از ۲۴ ساعت برای پیشبینی ۱۲ ساعت بعدی به دست آمده است. اگر فقط یک ساعت را پیشبینی کنیم، نتایج بسیار بهتر خواهند بود، همانطور که در نمودار دوم میبینیم.
فضای زیادی برای بازی با پارامترهای Transformer وجود دارد، مانند تعداد لایههای رمزگذار و رمزگشا و غیره. هدف این مدل، ارائه یک مدل کامل نبوده است و با تنظیم و آموزش بهتر، احتمالاً نتایج بهبود مییابند.
استفاده از GPUها میتواند کمک بزرگی برای تسریع آموزش باشد.


