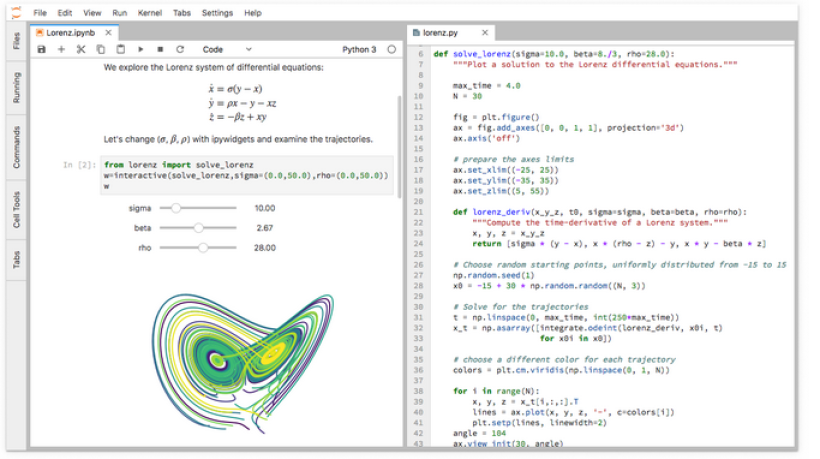
ژوپیتر لب JupyterLab جدید منتشر شد
مفتخریم به اطلاع شما برسانیم که در حال حاضر ژوپیتر لب در دسترس کاربران قرار گرفته است، رابط کاربری مبتنی بر وب نسل بعدی ژوپیتر لب برای استفاده روزان ...
مفتخریم به اطلاع شما برسانیم که در حال حاضر ژوپیتر لب در دسترس کاربران قرار گرفته است، رابط کاربری مبتنی بر وب نسل بعدی ژوپیتر لب برای استفاده روزان ...

ژوپیترنوتبوکها یکی از مهمترین محیطهای توسعه پایتون و از محبوبترین ابزارها درزمینهٔ دادهکاوی یا یادگیری ماشین (یادگیری عمیق)هستند.

اخیراً ، من روی نسخه ی دمو محاسبات پیشرفتهای کار می کردم که از یادگیری ماشینی برای تشخیص ناهنجاری ها در سایت یک کارخانه مورد استفاده قرار میگرفت. ا ...

مرور کلی JupyterLab یک محیط کدنویسی فوق العاده برای انجام کارهای مربوط به علم داده میباشد.این 10 دلیل افراد را قانع میکند که برای کدنویسی علم ...