
اخیراً ، من روی نسخه ی دمو محاسبات پیشرفتهای کار می کردم که از یادگیری ماشینی برای تشخیص ناهنجاری ها در سایت یک کارخانه مورد استفاده قرار میگرفت. این نسخه دمو در واقع بخشی از طرح راه حل صنعتی هستند که در سال گذشته ارائه شده بودند. بر اساس مستندات GitHub نقشه ساخت یا بلوپرینت ها امکان اعلام مشخصاتی را که می تواند در لایه ها سازماندهی شود فراهم می کند و تمام اجزای مورد استفاده در لبه ساختارمرجع ، مانند سخت افزار ، نرم افزار ، ابزارهای مدیریت و تجهیز ابزار را مشخص می کند.
در ابتدای شروع پروژه ، من فقط درکی کلی از یادگیری ماشینی داشتم وحقیقتا دانش تخصصی انجام کار مفید با آن را نداشتم به همچنین اگرچه در مورد نوت بوک های ژوپیتر چیزهای زیادی شنیده بودم اما واقعاً نمی دانستم آنها دقیقا چی هستند و چگونه باید از آنها استفاده کرد.
از این رو مطالعه این این مقاله برای توسعه دهندگانی که می خواهند یادگیری ماشینی و نحوه انجام آن توسط نوت بوک های ژوپیتر را بفهمند، بسیار مفید خواهد بود. در این مقاله با ساخت یک مدل یادگیری ماشینی برای تشخیص ناهنجاری در داده های ارتعاش پمپ های مورد استفاده در یک کارخانه ، توسط نوت بوک های ژوپیتر آشنا خواهید شد. خوشبختانه برای مطالعه بیشتر و آشنایی با نحوه ساخت مدل های ML ، منابع بسیار زیادی در دسترس است.
نوت بوک ژوپیتر چیست؟
نوت بوک های محاسباتی به عنوان نوت بوک های آزمایشگاهی الکترونیکی برای مستندسازی رویه ها ، داده ها ، محاسبات و یافته ها مورد استفاده قرار میگیرند محیط توسعه ژوپیتر یا به اصطلاح دفترچه ژوپیتر و یا نوت بوک ژوپیتر یک محیط محاسباتی تعاملی است که یک محیط برنامه نویسی برای توسعه برنامه های کاربردی «علم داده» Data Science) ) فراهم می کند.
نوت بوک ژوپیتر کد های نرم افزاری، خروجی محاسباتی ، متن توضیحی و محتوای غنی(متنی که دارای کدهای معرفی کننده ی ایتالیک ، حروف سیاه و شکلهای دیگر حروف است) را در یک سند واحد ترکیب می کنند. نوت بوک ها امکان ویرایش و اجرای کد در مرورگر و نمایش نتایج محاسبه را در لحظه دارند. یک نوت بوک با پسوند .ipynb ذخیره می شود. پروژه نوت بوک ژوپیتر از ده ها زبان برنامه نویسی پشتیبانی می کند ، نام آن نشان دهنده پشتیبانی آن از جولیا Ju)) و پایتون Python (Py), و R است.
می توانید یک نوت بوک را با استفاده از یک سندباکس عمومی (سندباکس (Sandbox) محیطی است که معمولا برای تست بخشهای جدید یک نرم افزار یا اجرای ایمن نرم افزارها بدون اینکه محیط اصلی تحت تأثیر آن قرار بگیرد به کار میرود) یا فعال کردن روی سرور خود مانند ژوپیتر هاب امتحان کنید. ژوپیتر هاب نوت بوک هایی را برای چندین کاربر ارائه می دهد که میتواند نمونه های متعددی از سرور نوت بوک ژوپیتر تک کاربره را ایجاد ، مدیریت و پروکسی کند. در این مقاله ، ژوپیتر هاب بر روی Kubernetes اجرا شده است.
داشبورد نوت بوک ژوپیتر
هنگامی که سرور نوت بوک برای اولین بار راه اندازی می شود ، یک برگه مرورگر جدید باز می شود که داشبورد نوت بوک را نشان می دهد. داشبورد به عنوان صفحه اصلی نوت بوک های شما عمل می کند. هدف اصلی آن نمایش بخشی از سیستم فایل در دسترس کاربر و ارائه نمای کلی از هسته های در حال اجرا ، پایانه ها و خوشه های موازی است. شکل 1 یک داشبورد نوت بوک را نشان می دهد.

شکل 1: داشبورد نوت بوک.
در ادامه با بخش های اجزای داشبورد نوت بوک ها آشنا خواهید شد:
برگه فایل ها Files tab
برگه Files نمای سیستم فایل را در اختیار کاربر قرار می دهد. این نما معمولاً ریشه در پوشه ای دارد که سرور نوت بوک در آن راه اندازی شده است.
افزودن نوت بوک- Adding a notebook
یک نوت بوک جدید می تواند با کلیک روی دکمه New ایجاد شود یا با کلیک روی دکمه بارگذاری، بارگذاری شود.
برگه در حال اجرا- Running tab
برگه در حال اجرا نوت بوک هایی را که در حال حاضر برای سرور شناخته شده است را نمایش می دهد.
کار با نوت بوک ژوپیتر
هنگامی که یک نوت بوک باز می شود ، یک برگه مرورگر جدید ایجاد می شود که رابط کاربری نوت بوک را ارائه می دهد. اجزای رابط در بخشهای زیر توضیح داده شده است.
سرتیتر- Header
در بالای سند نوت بوک یک سربرگ وجود دارد که شامل عنوان دفترچه ، نوار منو و نوار ابزار است ، همانطور که در شکل 2 نشان داده شده است.

شکل 2: سرتیتر نوت بوک.
بدنه- Body
بدنه یک نوت بوک از سلول ها تشکیل شده است. سلولها را می توان به هر ترتیبی وارد و به دلخواه ویرایش کرد. محتویات سلولها در انواع زیر قرار می گیرند:
- سلولهای مارک داون Markdown : اینها حاوی متنی با قالب بندی نشانه گذاری ، توضیح کد یا حاوی سایر محتوای رسانه های غنی هستند.
- سلول های کد Code cells : اینها شامل کد اجرایی هستند.
- سلول های خام Raw cells : این موارد زمانی مورد استفاده قرار می گیرند که نیاز به افزودن متن به صورت خام ، بدون اجرا یا تغییر باشد.
کاربران می توانند سلول های نشانه گذاری و متن را بخوانند و سلول های کد را اجرا کنند. شکل 3 نمونه هایی از سلول ها را نشان می دهد.

شکل 3: نمونه هایی از سلول ها.
ویرایش و اجرای سلول
رابط کاربری نوت بوک مودال است. این بدان معناست که صفحه کلید بسته به نوع حالت نوت بوک عملکرد متفاوتی دارد. یک نوت بوک دارای دو حالت است: ویرایش و فرمان.
هنگامی که یک سلول در حالت ویرایش است ، در قسمت ویرایشگر است و دارای حاشیه سلول سبز ، همانطور که در شکل 4 نشان داده شده است . در این حالت ، شما می توانید مانند یک ویرایشگر متنی معمولی در سلول تایپ کنید.

شکل 4: یک سلول در حالت ویرایش.
هنگامی که یک سلول در حالت فرمان است ، دارای حاشیه سلول آبی است ، همانطور که در شکل 5 نشان داده شده است. در این حالت ، می توانید از میانبرهای صفحه کلید برای انجام کارهای نوت بوک و سلول استفاده کنید. به عنوان مثال ، فشار دادن Shift+Enter در حالت فرمان ، سلول فعلی را اجرا می کند.

شکل 5: یک سلول در حالت فرمان.
سلول های کد در حال اجرا
برای اجرای سلول کد:
روی هر نقطه در قسمت [] در سمت چپ بالای سلول کد کلیک کنید. با این کار سلول وارد حالت فرمان می شود.
Shift+Enter را فشار دهید یا Cell—> Run را انتخاب کنید.
سلول های کد به ترتیب اجرا می شوند. یعنی هر سلول کد تنها پس از اجرا شدن تمام سلول های کد قبل از آن اجرا می شود.
شروع کار با نوت بوک ژوپیتر
پروژه نوت بوک ژوپیتر از بسیاری از زبان های برنامه نویسی پشتیبانی می کند. ما در این مثال از IPython استفاده می کنیم. این زبان مشابه پایتون است اما تجربه تعاملی بیشتری را ارائه می دهد. برای انجام محاسبات ریاضی مورد نیاز برای یادگیری ماشین به کتابخانه های پایتون زیر نیاز دارید:
- NumPy : برای ایجاد و دستکاری بردارها و ماتریس ها.
- Pandas: برای تجزیه و تحلیل داده ها و درگیری و یا خراب کردن داده ها. پاندا داده هایی مانند فایل CSV یا پایگاه داده را می گیرد و از آن یک شی پایتون به نام DataFrame ایجاد می کند. دیتا فریم ساختار داده مرکزی در API Pandas است و شبیه صفحه گستردهای به شرح زیر است:
- DataFrame : داده ها را در سلول ها ذخیره می کند.
- یک DataFrame ستونها (معمولاً) و سطرهای شماره گذاری شده را نامگذاری کرده است.
- Matplotlib: برای تجسم داده ها.
- اسکلرن Sklern: برای یادگیری تحت نظارت و بدون نظارت. این کتابخانه ابزارهای مختلفی را برای انطباق مدل model fitting ، پیش پردازش داده ها ، انتخاب مدل و ارزیابی مدل ارائه می دهد. دارای الگوریتم ها و مدلهای یادگیری ماشین داخلی به نام برآوردگر estimators است. هر برآوردگر را می توان با استفاده از روش برازش خود بر روی برخی داده ها نصب کرد.
استفاده از نوت بوک ژوپیتر برای یادگیری ماشین
در این مقاله ما از مدل MANUela ML به عنوان نمونه نوت بوک برای بررسی اجزای مختلف مورد نیاز برای یادگیری ماشین استفاده خواهیم کرد. داده های مورد استفاده برای آموزش مدل در فایل raw-data.csv قرار دارد.
این نوت بوک از روند کاری که در شکل 6 نشان داده شده است پیروی می کند.
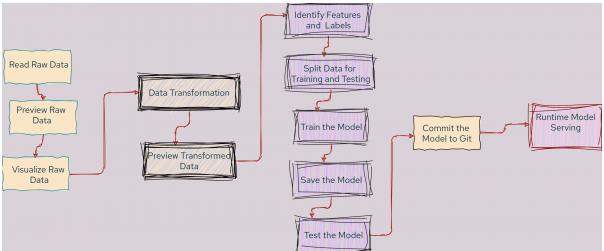
شکل 6: گردش کار نوت بوک برای یادگیری ماشین.
مرحله 1: داده های خام را کاوش کنید
از یک سلول کد برای وارد کردن کتابخانه های مورد نیاز پایتون استفاده کنید. سپس ، فایل داده های خام (raw-data.csv ) را به DataFrame با سری زمانی ، شناسه پمپ ، مقدار ارتعاش و برچسب نشان دهنده ناهنجاری تبدیل کنید. کد پایتون مورد نیاز در سلول 7 در شکل 7 نشان داده شده است.

شکل 7: وارد کردن کتابخانه ها و تبدیل داده های خام.
اجرای سلول یک DataFrame با داده های خام تولید می کند که در شکل 8 نشان داده شده است.
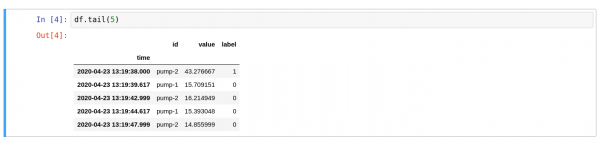
شکل 8: قاب داده با داده های خام.
اکنون DataFrame را تجسم کنید. نمودار بالا در شکل 9 زیر مجموعه ای از داده های ارتعاش را نشان می دهد. نمودار پایین داده های دارای برچسب دستی با ناهنجاری (1 = ناهنجاری ، 0 = طبیعی) را نشان می دهد. اینها ناهنجاری هایی هستند که مدل یادگیری ماشین باید آنها را تشخیص دهد.
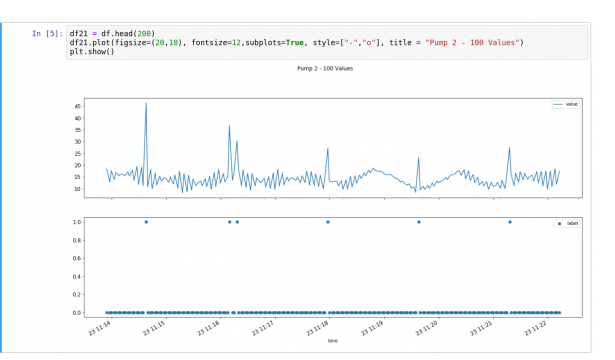
شکل 9: تجسم داده های خام و ناهنجاری ها.
قبل از تجزیه و تحلیل، داده های خام باید تغییر شکل داده ، تمیز شوند و به فرمت های مناسب تر برای تجزیه و تحلیل تبدیل شوند. این فرایند را جمع آوری داده ها یا داده کاوی می نامند.
ما داده های سری زمانی خام را به قسمت های کوچکی تبدیل می کنیم که می تواند برای یادگیری تحت نظارت استفاده شود. شکل 10 کد نشان داده شده است.

شکل 10: ایجاد یک data frame جدید.
ما می خواهیم داده ها را به یک DataFrame جدید به قسمت های با طول 5 تبدیل کنیم. شکل 11 نمونه ای از مجموعه داده های سری زمانی را نشان می دهد.
شکل 11: نمونه ای از داده های سری زمانی.
اگر داده های نمونه خود را به قسمت هایی با طول = 5 تبدیل کنیم ، به نتایج مشابه شکل 12 می رسیم.
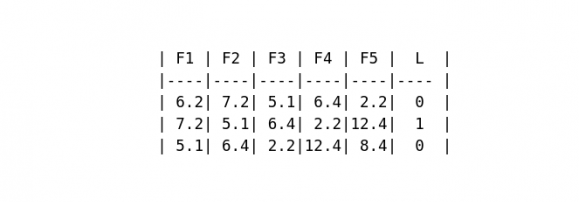
شکل 12: data frame جدید با قسمت ها.
اکنون با استفاده از کد شکل 13 داده های سری زمانی خود را چند قسمت میکنیم.
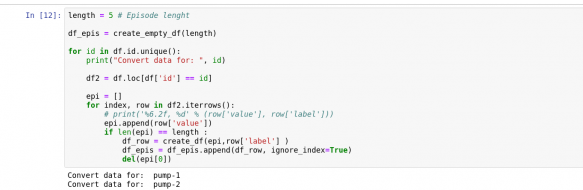
شکل 13: تبدیل داده ها به چند قسمت
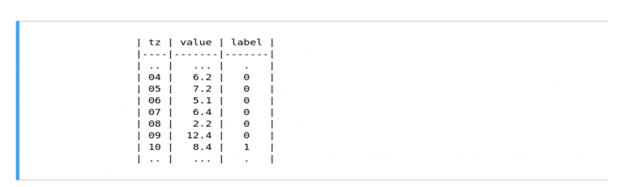
شکل 14 داده ها را با قسمت هایی به طول 5 و برچسب در ستون آخر بررسی می کند.
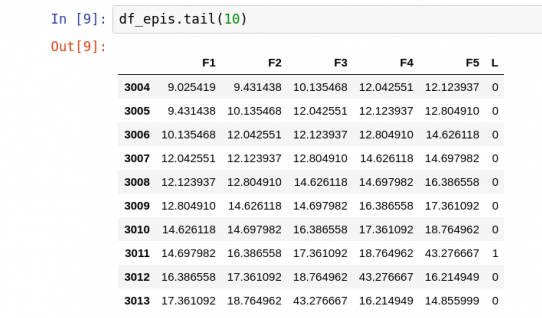
شکل 14: قسمت هایی به طول 5 و برچسب در ستون آخر.
توجه: در شکل 14 ، ستون F5 آخرین مقدار داده است ، در حالی که ستون F1 قدیمی ترین داده ها برای یک قسمت معین است. برچسب L نشان می دهد که آیا ناهنجاری وجود دارد یا خیر.
داده ها اکنون برای یادگیری تحت نظارت آماده است.
مرحله 2: ویژگی و ستون های هدف
مانند بسیاری از کتابخانه های یادگیری ماشین ، Sklearn به ستون های ویژگی جداگانه (X) و هدف ( Y) نیاز دارد. مطابق شکل 15 داده های شما را به ستون های ویژگی و هدف تقسیم می کند.
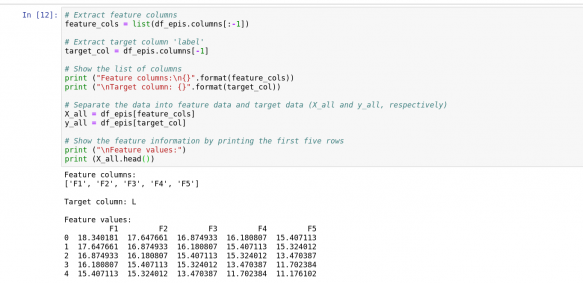
شکل 15: تقسیم داده ها به ستون های ویژگی و هدف.
مرحله 3: آموزش و آزمایش مجموعه داده ها
یک عمل خوب این است که مجموعه داده های خود را به دو زیر مجموعه تقسیم کنید: یکی برای آموزش یک مدل و دیگری برای آزمایش مدل آموزش دیده.
هدف ما ایجاد مدلی است که به خوبی به داده های جدید تعمیم داده شود. مجموعه آزمایشی ما به عنوان نماینده داده های جدید عمل می کند. همانطور که در شکل 16 نشان داده شده است ما مجموعه داده ها را به 67 درصد برای مجموعه های آموزشی و 33 درصد برای مجموعه آزمایش تقسیم کردهایم.
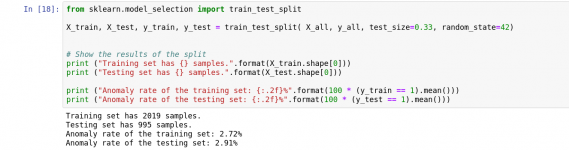
شکل 16: تقسیم داده ها به مجموعه داده های آموزشی و آزمایشی.
ما می توانیم مشاهده کنیم که میزان ناهنجاری برای هر دو مجموعه تمرین و آزمون مشابه است. یعنی مجموعه داده ها نسبتاً مساوی تقسیم شده است.
مرحله 4: آموزش مدل سازی
ما آموزش مدل را با الگوریتم درخت تصمیمگیری طبقه بندی شده DecisionTreeClassifier انجام می دهیم. درخت تصمیم گیری یک روش یادگیری تحت نظارت است که برای طبقه بندی و رگرسیون استفاده می شود. هدف ایجاد مدلی است که ارزش متغیر هدف را با یادگیری قوانین تصمیم گیری ساده که از ویژگی های داده استنباط می شود ، پیش بینی کند.
DecisionTreeClassifier کلاسی است که طبقه بندی چند کلاسی را بر روی یک مجموعه داده انجام می دهد ، اگرچه در این مثال ما از آن برای طبقه بندی در یک کلاس واحد استفاده کرده ایم. DecisionTreeClassifier دو آرایه به عنوان ورودی می گیرد: یک آرایه X به عنوان ویژگی و یک آرایه Y به عنوان برچسب. پس از نصب ، می توان از مدل برای پیش بینی برچسب مجموعه داده های آزمایش استفاده کرد. شکل 17 کد ما را نشان می دهد.
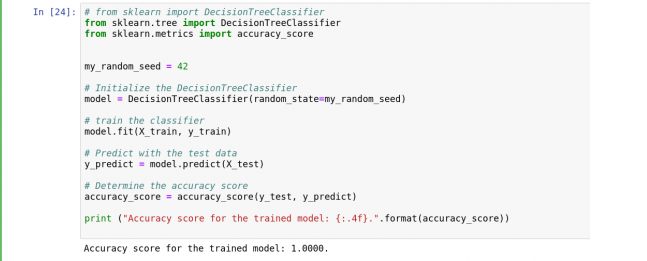
شکل 17: آموزش مدل با DecisionTreeClassifier.
ما می توانیم ببینیم که مدل از نظر دقت نمره بالایی را کسب کرده است.
مرحله 5: مدل را ذخیره کنید
مدل را ذخیره کرده و مجدداً بارگذاری کنید تا مطمئن شوید که کار می کند ، همانطور که در شکل 18 نشان داده شده است.
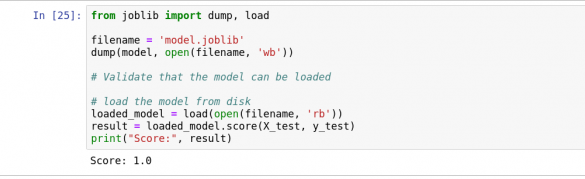
شکل 18: ذخیره مدل.
مرحله 6: استنباط با مدل
اکنون که مدل یادگیری ماشین را ایجاد کرده ایم ، می توانیم از آن برای استنباط در داده های زمان واقعی استفاده کنیم.
در این مثال ، ما از Seldon برای ارائه مدل استفاده می کنیم. برای اینکه مدل ما تحت سلدون اجرا شود ، ما باید کلاسی ایجاد کنیم که متد پیش بینی داشته باشد. روش پیش بینی می تواند یک آرایه NumPy را دریافت کرده و نتیجه پیش بینی را به صورت زیر بازگرداند:
- یک آرایه NumPy
- لیستی از مقادیر
- یک رشته بایت
کد ما در شکل 19 نشان داده شده است.

شکل 19: استفاده از سلدون برای ارائه مدل یادگیری ماشین.
در نهایت همانطور که در شکل 20 نشان داده شده است ، باید آزمایش کنیم که آیا مدل می تواند ناهنجاری ها را برای لیستی از مقادیر پیش بینی کند با خیر.
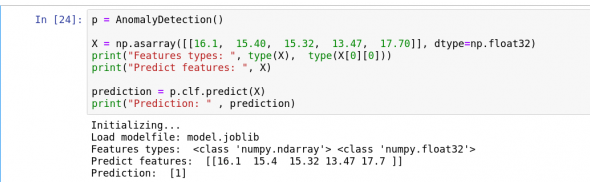
شکل 20: استنتاج با استفاده از مدل.
ما می توانیم ببینیم که مدل برای نتیجه گیری نمره بالایی را کسب کرده است.
حرف اخر
برای تجربه این محیط جذاب میتوانید از طریق لینک زیر اقدام کنید:
افکارتان را باما در میان بگذارید