مدلسازی زبان در هوش مصنوعی، بر توسعه سیستمهایی متمرکز است که قادر به درک، تفسیر و تولید زبان انسانی هستند. این حوزه، کاربردهای گوناگونی از جمله ترجمه ماشینی، خلاصه سازی متن و موارد گفتمانی را در بر میگیرد. محققان به دنبال ایجاد مدلهایی هستند که تواناییهای زبانی انسان را تقلید کنند تا تعامل روان بین انسان و ماشین را ممکن سازند. پیشرفتها در این زمینه، منجر به توسعه مدلهای پیچیده و بزرگ شده است، که نیازمند منابع محاسباتی قابل توجهی هستند و قطعا معماری Memory3 یکی از این پیشرفتهای جدید است که در ادامه بیشتر با آن آشنا میشویم.
پیچیدگی و حجم فزاینده مدلهای زبانی بزرگ «LLM»، منجر به هزینههای قابل توجه در مواردی همچون آموزش و نتیجه سازی میشود. این هزینهها ناشی از لزوم رمزگذاری حجم عظیمی از دادهها در پارامترهای مدل است که هم از نظر منابع پرهزینه و هم گران از نظر محاسباتی هستند.
با افزایش تقاضا برای مدلهای قدرتمندتر، چالش مدیریت این هزینهها پررنگتر میشود. رسیدگی به این مشکل برای توسعه پایدار فناوریهای مدلسازی زبان، امری حیاتی است.
روشهای موجود برای کاهش این هزینهها، شامل بهینه سازی جنبههای مختلف مدلهای زبانی بزرگ میباشد، مثلا بهینه سازی در معماری، کیفیت دادهها و موازی سازی آنها. به عنوان نمونه مدلهای نسل توسعه دیده با بازیابی «retrieval augmented generation یا RAG»، از پایگاههای دانش خارجی برای کاهش بار روی پارامترهای مدل خود استفاده میکنند.
که با این حال، این مدلها هنوز هم به شدت به پارامترهای بزرگ وابسته هستند و همین امر کارایی آنها را محدود میکند. از رویکردهای دیگر میتوان به بهبود کیفیت داده و استفاده از سخت افزارهای پیشرفته اشاره نمود، اما تمام این راه حلها تنها بخشی از چالش هزینههای بالای محاسباتی را حل میکنند.
معماری Memory3 انقلابی در پرفورمنس عملکرد مدلهای زبانی ایجاد میکند
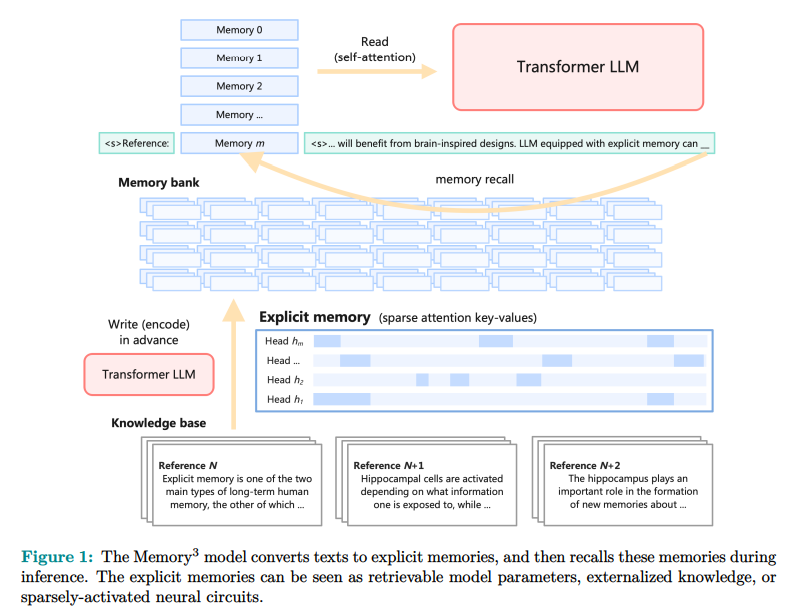
مدل «Memory3» توسط محققانی از مؤسسه تحقیقات الگوریتمهای پیشرفته در شانگهای «Moqi Inc»، و مرکز تحقیقات یادگیری ماشین «Machine Learning» در دانشگاه پکن معرفی شده است. این رویکرد نوآورانه، حافظه صریح را در LLM ها ادغام میکند. این مدل، بخش قابل توجهی از دانش خود را به صورت خارجی نگهداری میکند تا «LLM» بتواند اندازهٔ پارامتری کوچکتری داشته باشد. معرفی حافظه صریح، یک تحول پارادایمی در نحوه ذخیره و بازیابی دانش در مدلهای زبانی است.
«Memory3» از حافظههای صریح «آشکار» استفاده میکند که نسبت به پارامترهای مدل سنتی، ذخیره و فراخوانی آنها ارزانتر است. این طراحی شامل یک مکانیزم کاهش تراکم حافظه و یک طرح پیش آموزش دو مرحلهای برای تسهیل تشکیل حافظه کارآمد است. این مدل، متون را به حافظههای صریح تبدیل میکند که میتوانند در زمان نتیجه گیری بازیابی شوند و هزینههای محاسباتی کلی را کاهش دهند. معماری «Memory3» به گونهای طراحی شده که با مدلهای زبان بزرگ موجود که مبتنی بر مبدلها هستند «Transformer-based LLMs» سازگار باشد و صرفا با یک تنظیم جزئی قابل بهره برداری باشد.
این انعطاف پذیری اطمینان میدهد که مدل «Memory3» میتواند بدون نیاز به اصلاحات گسترده سیستماتیک، به طور فراگیری مورد استفاده قرار گیرد. پایگاه دانش آن شامل ۱٫۱ × ۱۰^۸ بخش متنی با طول حداکثر ۱۲۸ توکن میباشد که به صورت کارآمد ذخیره و پردازش میشوند.
مدل «Memory3»، با ۲٫۴ میلیارد پارامتر جاسازی نشده، عملکرد بهتری نسبت به «LLM» ها و مدلهای «RAG» بزرگتر از خود داشته است. این مدل، عملکرد بهتری در بنچمارک نشان داده و کارایی و دقت بهتری را به نمایش گذاشته است. به طور خاص، «Memory3» سرعت رمزگشایی بالاتری نسبت به مدلهای «RAG» دارد، زیرا به فرآیندهای بازیابی متن به صورت گسترده متکی نیست.
علاوه بر این، عملکرد آن در وظایف حرفهای که نیازمند بازیابی با فرکانس بالای حافظههای صریح میباشد، نشان میدهد که قدرت و انعطاف پذیری این مدل برای کاربردهای مختلف قابل استفاده است. ادغام حافظههای صریح، بار محاسباتی را به میزان قابل توجهی کاهش میدهد و پردازش سریعتر و کارآمدتری را ممکن میسازد.
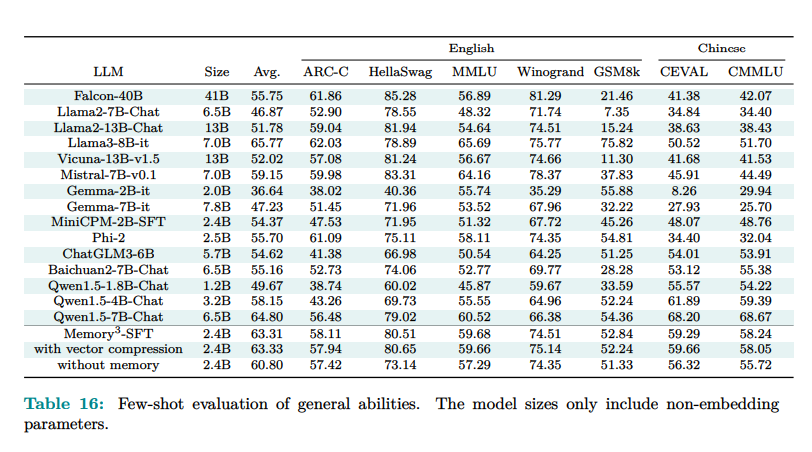
آنچه مشخص است مدل «Memory3» نتایج چشمگیری را به نمایش گذاشته است. این مدل با استفاده از حافظه صریح، امتیاز متوسط خود را ۲٫۵۱ درصد بهبود داده و در مقایسه با مدلهایی که این ویژگی را نداشتند به مراتب بهتر عمل کرده است. به عنوان مثال امتیاز ۸۳٫۳ در «HellaSwag» و ۸۰٫۴ در «BoolQ» را کسب کرده، این در حالیست که یک مدل بزرگتر با ۹٫۱ میلیارد پارامتر امتیازهای ۷۰٫۶ و ۷۰٫۷ را کسب کرده است.
ضمنا سرعت رمزگشایی این مدل بدون استفاده از حافظه ۳۵٫۲ درصد کندتر بود که نشان دهنده استفاده کارآمد از حافظه است. علاوه بر این، مکانیزم حافظه صریح، نیاز به فضای ذخیره سازی حافظه کل را از ۷٫۱۷ پتابایت به ۴۵٫۹ ترابایت کاهش داده که آن را برای کاربردهای در مقیاس بزرگ، عملیتر میسازد.
در پایان، مدل «Memory3» یک پیشرفت قابل توجه در کاهش هزینه و پیچیدگی آموزش و اجرای مدلهای زبانی بزرگ محسوب میشود. محققان با برون سپاری بخشی از دانش به حافظههای صریح، یک راه حل کارآمد به همراه قابلیت مقیاس پذیری ارائه کردند که عملکرد و دقت بالایی را حفظ میکند. این رویکرد نوآورانه، چالش هزینههای محاسباتی در مدلسازی زبان را برطرف میکند و راه را برای فناوریهای هوش مصنوعی پایدارتر و در دسترستر هموار میسازد.
یکی از مزایای دیگر مدل «Memory3»، قابلیت آن در کاهش اثرات زیست محیطی فناوریهای هوش مصنوعی است. با کاهش نیاز به منابع محاسباتی عظیم، این مدل گام مهمی در راستای دستیابی به فناوریهای پایدارتر و سازگارتر با محیط زیست برمی دارد. کاهش مصرف انرژی، تولید گازهای گلخانهای و کربن ناشی از آموزش و اجرای مدلهای بزرگ، میتواند تاثیر قابل توجهی بر حفاظت از منابع طبیعی و مبارزه با تغییرات آب و هوایی داشته باشد.
علاوه بر این، مدل «Memory ۳» امکان دسترسی گستردهتر به فناوریهای هوش مصنوعی پیشرفته را فراهم میکند. با کاهش هزینههای سرسام آور محاسباتی، این مدل میتواند برای سازمانهای کوچکتر و محدودتر از نظر بودجه نیز در دسترس باشد. این امر به نوبه خود، نوآوری و خلاقیت را در حوزه هوش مصنوعی تقویت میکند و فرصتهای جدیدی را برای استفاده از این فناوری در زمینههای گوناگون از جمله آموزش، پزشکی، تجارت و غیره ایجاد مینماید.






