
نوتبوکها یکی از مهمترین محیطهای توسعه پایتون و از محبوبترین ابزارها درزمینهٔ دادهکاوی یا یادگیری ماشین (یادگیری عمیق)هستند. اما لازم ست بدانید که مدیریت سریع چنین ابزار قدرتمندی چندان ساده نیست. توانایی تعامل سریع با دادههایمان (تغییر سلولهای کد، اجرا و تکرار) یکی از دلایل مهمی است که نباید نوت بوکهایمان دچار یک درهمتنیدگی مبهم از متغیرهای گوناگون باشند که درک آنها حتی برای نویسندهاش نیز سخت است. در این مقاله قصد داریم شما را با مفهوم و روشهای کد نویسی مرتب (Clean code) آشنا کنیم.
من بهشخصه در همان شش سال پیش که شروع به یادگیری پایتون کردم با نوت بوک های Jupyter هم آشنا شدم. چیزی که بیشتر از همه مرا شگفتزده کرد این بود که چگونه مردم میتوانند کدی بنویسند که دیگران به آن اعتماد کنند و از آن استفاده کنند. بررسی پروژههایی مانند scikit-learn الهامبخش من برای شروع اولین پروژه منبع باز من شد. بعد از آن به سرعت بسیاری از روشهای مهندسی نرمافزار مانند مدولارسازی و پکیجینگ را یاد گرفت اما هنوز مطمئن نبودم که چطور آن را درزمینهٔ دادهکاوی به کار بگیریم تا اینکه اکوسیستم ابزارهای داده پایتون به بلوغ رسید و من شروع به کشف چگونگی ساخت این اکوسیستم کردم. در ادامه با من همراه باشید تا ببینیم که چرا کد نویسی تمیز مهم است؟ و چگونه کدهای تمیزی بنویسیم و با راهکارهایی برای نوشتن نوت بوک های تمیز در ژوپیتر آشنا شوید.
10 توصیه برای نوشتن نوت بوکهای خوانا و قابل نگهداری
آنچه در ادامه میخوانید:
- قفلکردن dependencies
- پکیجینگ پروژه
- مدولار کردن کدها
- مراقبت از ساختارهای داده قابلتغییر
- بارگذاری مجدد خودکار کد از ماژولهای خارجی
- تست واحد
- سازماندهی سکشن ها
- استفاده از یک خط کد
- استفاده از یک فرمت کننده خودکار کد
- نوشتن نوتبوکهای کوتاهتر
قفلکردن dependencies
اجازه دهید پیش از صحبت کردن در مورد نوت بوک های تمیز، به مدیریت dependency ها بپردازیم. خود من بارها زمانی که سعی کردهام یک نوت بوک قدیمی را اجرا کنم (توسط خودم یا شخص دیگری نوشتهشده بود ) با چندین خطای ModuleNotFound برخورد کردم. حتی پس از اجرای pip install برای هر یک از آنها نیز مواجهشدن با ارورهای غیرمعمولی مانند این اجتنابناپذیر است. دلیلش هم مشخص است، چون بسته API تغییر کرده و دیگر با کد سازگار نیست.
برای جلوگیری از خرابی نوت بوک ها که به دلیل dependency های ازدسترفته به وجود میآید، هر بسته شخص ثالثی (third-party package ) که استفاده میکنیم باید در یک فایل requirements.txt ( یا environment.yml اگر از conda استفاده میکنیم) ثبت شود. برای مثال، یک requirements.txt معمولی ممکن است به شکل زیر باشد:

پس از نصب dependency ها در یک محیط مجازی (همیشه از محیطهای مجازی استفاده کنید!)، میتوانیم به فهرستی جامعی از تمام dependency های نصب شده از طریق زیر دسترسی پیدا کنیم:

و requirements.lock.txt ما به شکل زیر است:
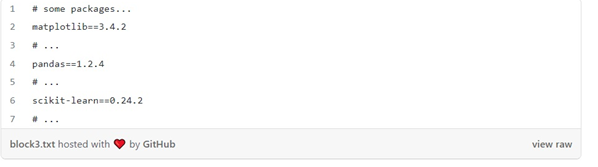
چرا requirements.lock.txt اینهمه خط دارد؟ هر پکیج دارای مجموعهای از dependency ها است (بهعنوانمثال، پانداها به NumPy نیاز دارند). ازاینرو، pip freeze لیستی از تمام پکیجهای لازم برای اجرای پروژه ما را ایجاد میکند. هر خط همچنین شامل نسخه نصب شده خاصی است. بنابراین، اگر بخواهیم مجدداً نوت بوک خود را یک سال بعد اجرا کنیم، با مشکل سازگاری مواجه نخواهیم شد زیرا همان نسخهای را که در طول توسعه از آن استفاده کرده بودیم را نصب میکنیم.
حتی اگر پروژه ما شامل چندین نوت بوک باشد، یک requirements.txt کافی است. با این حال، به خاطر داشته باشید که هر چه پروژه ما dependency های بیشتری داشته باشد، شانس بیشتری برای درگیری با dependency ها دارد (بهعنوانمثال، تصور کنید پانداها به NumPy نسخه 1.1 نیاز دارند، اما scikit-learn به NumPy نسخه 1.2 نیاز دارند). به یاد داشته باشید که requirements.txt و requirements.lock.txt خود را بهروز نگه دارید: در صورت نیاز پکیجهای جدید اضافه کنید و اگر دیگر به آنها نیازی نداریدحتما آنها حذف کنید.
پکیجینگ پروژه
هنگام شروع به نوشتن یک نوت بوک، تعریف توابع یا کلاسها در فایل نوت بوک کاری وسوسهانگیز است، اما این کار پیچیدگیهای زیادی ایجاد میکند. اولاً، این روش در آینده وارد کردن چنین کدی را در نوت بوک دیگری غیرممکن میکند، و دوم، استدلال در مورد معنای آن را دشوار میکند (این تابعی است که داده ها را پردازش میکند یا آن را ترسیم میکند؟). یک تمرین بهتر این است که تعاریف تابع و کلاس خود را در یک فایل جداگانه نگه داریم و بعداً آنها را در نوت بوک خود وارد کنیم:
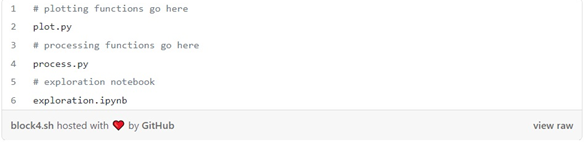
چنین طرحبندی سادهای تا زمانی که بخواهیم کد خود را در پوشهها سازماندهی کنیم خوب کار میکند:
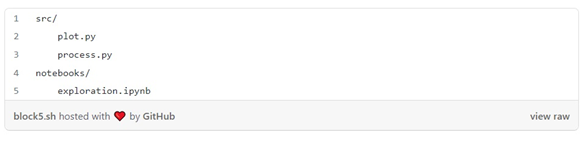
اگر exploration.ipynb را بازکنیم، دیگر نمیتوانیم import plot یا import process را انجام دهیم. به این دلیل که هنگام استفاده از import پایتون ابتدا به دنبال یک ماژول محلی (یعنی فایلی در همان فهرست) با آن نام میگردد، و سپس در site-packages (هنگام pip install {package} بستهها در آنجا ذخیره میشوند) . بنابراین، اگر میخواهیم پایتون کد ما را ایمپورت کند، باید به پایتون بگوییم کجا آن را جستجو کند. مطمئنم شما قبلاً این را دیدهاید:

ما به پایتون میگوییم که داخل ../src به دنبال ماژولها بگردد. با این کار ما میتوانیم plot.py و process.py را وارد کنیم. اما این کار شدیداً اشتباه است. تغییر sys.path شکستن کد ما را آسان میکند. فرض کنید میخواهیم کدی را وارد کنیم که در یک مکان خاص وجود دارد. اگر هر یک از فایلهای .py را جابهجا کنیم، باعث شکسته شدن نوت بوک خود میشویم.. خوشبختانه، یک راه قوی برای حل این مشکل وجود دارد و آن ایجاد یک بسته پایتون است.
بسته پایتون مجموعهای از فایلهای پایتون است که میتوانید با pip install {package} آن را نصب کنید. pip از پیکربندی پایتون مراقبت میکند تا بداند کجا باید دنبال آن کد بگردد. ایجاد یک پکیج ساده است. فقط شما نیاز دارید که یک فایل setup.py اضافه کنید:
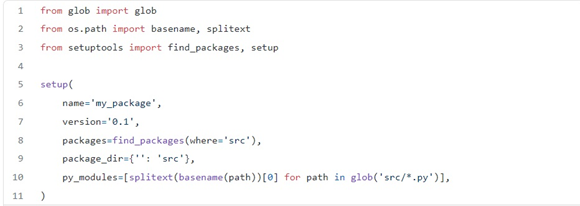
سپس، یک تغییر کوچک در طرحبندی پروژه خود ایجاد میکنیم و کد خود را در پوشه my_package/ قرار میدهیم و یک فایل __init__.py هم اضافه میکنیم:
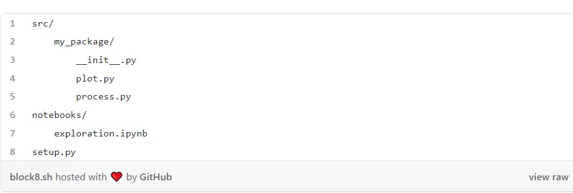
خودشه! حالا اگر به پوشه حاوی فایل setup.py بروید، میتوانید مانند زیر کار را انجام دهید:

بیایید ببینیم با این دستور چه اتفاقی میافتد. هنگام نصب یک بسته از طریق pip install {package} ، به pip میگوییم که به فهرست بسته پایتون Python Package Index برود ، بستهای را با نام درخواستی جستجو کند و آن را در بستههای سایت ذخیره کند.
اما pip میتواند از مکانهای دیگر هم نصب شود. به عنوان مثال، فرض کنید pip install را اجرا میکنیم. در این صورت، به pip میگوییم که از منبع موجود در دایرکتوری فعلی استفاده کند. با اجرای چنین دستوری کد را کپی میکند و آن را در site-packages در کنار هر بسته third-party دیگری ذخیره میکند. پس اگر ما آن را وارد کنیم، کپی را در site-packages میخواند:
اگر علامت یا پرچم –editable را اضافه کنیم، به pip میگوییم که کد را کپی نکند، بلکه آن را از مکان اصلی آن بخواند. این کار به ما این امکان را میدهد زمانی که تغییراتی را در کد خود ایجاد کنیم، پایتون از آخرین نسخه هنگام وارد کردن آن استفاده کند:
پس از نصب بسته ما، هر ماژول در پوشه src/my_package/ قابل ایمپورت کردن از هر دایرکتوری است:

حالا اگر به آنجا برویم، دیگر خبری از کلنجار رفتن با sys.path نیست!
مدولار کردن کدها
هنگام جستجوی داده ها، بیشتر کدها به این شکل هستند:
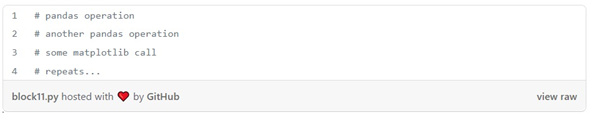
اما هر از گاهی، کدهایی وجود دارند که ساختار بیشتری دارند:
اسنیپتهایی Snippet که بیش از یکبار فراخوانی میشوند
اسنیپتهایی با ساختارهای کنترلی (به عنوان مثال، if, for)
برای اولین نوع، بهتر است آنها را به صورت توابع انتزاعی درآوریم و آنها را از نوت بوک خود فراخوانی کنیم. نوع دوم کمی ذهنیتر است و بستگی به پیچیدگی اسنیپتها دارد. اگر یک ساختار کنترلی با چند خط کد در بدنه آن دارید، بهتر است که آن را در نوت بوک بگذارید، اما اگر بیش از یک ساختار کنترلی با خطوط زیادی در بدنه دارید، حتی اگر فقط یکبار از آن استفاده میکنید بهتر است ابتدا یک تابع ایجاد کنید و سپس آن را در نوت بوک خود فراخوانی کنید.
یک نوت بوک تمیز عملاً مجموعهای از خطوط کد با ساختارهای کم یا بدون ساختار کنترل است. پیچیدگی یک نرم افزار با معیاری به نام پیچیدگی سیکلوماتیکی سنجیده میشود که میزان پیچیدگی یک برنامه را اندازه میگیرد. ازنظر شهودی، هرچه یک برنامه شاخههای بیشتری داشته باشد (مثلاً دستورات if )، پیچیدهتر است.
اندازهگیری پیچیدگی نوتبوکها در هر git push راهی برای جلوگیری از ورود نوتبوکهای بیشازحد پیچیده به پایگاه کد است، این بسته میتواند پیچیدگی سیکلوماتیک برنامههای پایتون را اندازهگیری کند:

در دستور قبلی، ما فقط بخش هایی از نوت بوک را با پیچیدگی 3 یا بالاتر گزارش میکنیم. این کار به ما اجازه میدهد تا ساختارهای کنترل ساده به وجود بیاوریم.
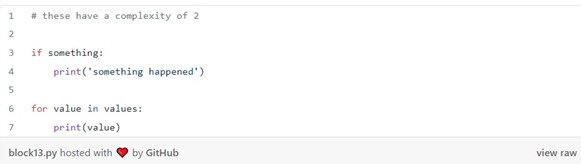
اما هر چیزی پیچیده تر از این (مانند یک ساختار کنترل تودرتو)، علامت گذاری می شود:

مراقبت از ساختارهای داده قابل تغییر
بیشتر ساختارهای داده ای که برای دستکاری داده ها data manipulation استفاده می شوند قابل تغییر هستند، به این معنی که شما می توانید مقادیر اولیه را تنظیم کنید و بعداً آنها را تغییر دهید. به مثال زیر توجه کنید:
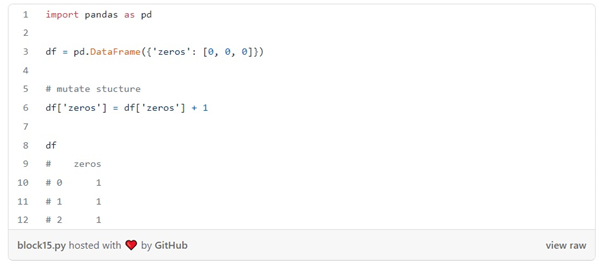
همانطور که در مثال قبلی می بینیم، ما یک چهارچوب داده (دیتا فریم) را با صفر مقداردهی کردیم اما سپس مقادیر را تغییر دادیم. در چنین قطعه کد کوتاهی، دیدن آنچه اتفاق می افتد آسان است: می دانیم که پس از دستکاری داده ها ، ستون zeros شامل یک ها می شود.
با این حال، اگر دستکاری داده ها در داخل توابع پنهان شوند، همین الگو باعث ایجاد مشکلاتی می شود. تصور کنید نوت بوک زیر را دارید:
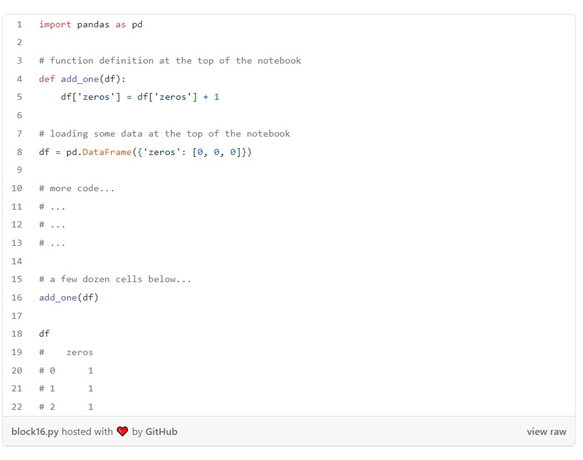
در این مثال، یک تغییر در داخل یک تابع اتفاق افتاده است. تا زمانی که به سلولadd_one(df) که دستکاری شده است برسید، حتی ممکن است به یاد نیاورید که add_one(df) ستون صفرها را تغییر داده است و خیال کنید که df همچنان صفر است! اگر تعریف تابع در فایل دیگری وجود داشته باشد، پیگیری این دستکاریها حتی پیچیدهترهم میشود.
دو راه برای جلوگیری از این نوع مشکلات وجود دارد. اولین مورد استفاده از توابع خالص است. توابع خالص توابعی هستند که هیچ گونه عوارض جانبی ندارند. مثلا اگر add_one را دوباره بنویسیم تا یک تابع خالص باشد به شکل زیر میشود:

به جای تغییر دیتا فریم ورودی ( df)اینبار یک کپی جدید ایجاد می کنیم، آن را تغییر می دهیم ومجددا آن را برمی گردانیم:
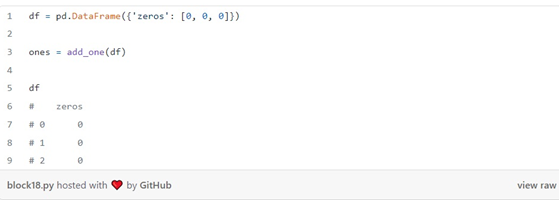
یکی از نکاتی که در این رویکرد وجود دارد این است که در این حالت ما حافظه زیادی را هدر می دهیم. زیرا هر بار که یک تابع را روی یک دیتا فریم اعمال می کنیم، یک کپی ایجاد می کنیم. کپی بیش از حد داده ها می تواند سرعت مصرف حافظه را به شدت بالا ببرد. یک راه حلجایگزین این است که در مورد تغییرهای خود صریح باشیم و همه تبدیل ها را در یک ستون معین ودر یک مکان واحد نگه داریم:
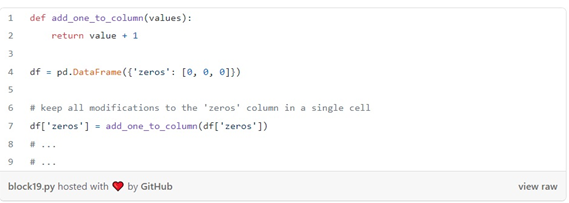
مثال قبلی ستون zeros را تغییر می دهد اما به روشی متفاوت: add_one_to_column یک ستون را به عنوان ورودی می گیرد و مقادیر تغییر یافته را برمی گرداند. تغییرخارج از تابع به روشی صریح اتفاق می افتد: df[‘zeros’] = add_one_to_column(df[‘zeros’]) با نگاه کردن به این کد، میتوانیم ببینیم که با اعمال تابع add_one_to_column در ستون zeros ، آن را تغییر میدهیم. اگر تبدیلهای دیگری به ستون zeros داشته باشیم، باید آنها را در همان سلول یا حتی بهتر از آن در یک تابع نگه داریم. این رویکرد از نظر حافظه کارآمدتر است، اما از طرفی برای جلوگیری از بروز اشکالات باید بسیار مراقب باشیم.
بارگذاری مجدد خودکار کد از ماژول های خارجی
یکی از مواردی که ممکن است قبلاً امتحان کرده باشید این است که ابتدا یک تابع/کلاس را به یک نوت بوک وارد کنید، کد منبع آن را ویرایش کنید و دوباره آن را وارد کنید. متأسفانه، چنین راه حلی همیشه کار نمی کند. ایمپورت پایتون دارای سیستم کش است. هنگامی که چیزی را وارد میکنید، با وارد کردن مجدد ،پایتون آن را از منبع جدید بارگیری نمیکند، بلکه از تابع/کلاس وارد شده قبلی استفاده میکند. با این حال، یک راه ساده برای فعال کردن بارگیری مجدد خودکار ماژول با افزودن کد زیر در بالای یک نوت بوک وجود دارد:

از آنجایی که این کار از امکانات بومی پایتون نیست، با چند ویژگی عجیب و غریب همراه است. اگر میخواهید درباره محدودیتهای این رویکرد بیشتر بدانید، مستندات IPython را بررسی کنید.
تست واحد
با توجه به سرعتی که دانشمندان داده برای انجام کارها دارند (یعنی بهبود عملکرد مدل)، جای تعجب نیست که اغلب ما از آزمایشها غافل میشویم. درحالی که اگر به نوشتن تست ها عادت کنید، سرعت توسعه شما را به شدت افزایش می دهد.
برای مثال، اگر در حال کار بر روی یک تابع برای تمیز کردن یک ستون در یک دیتا فریم هستید، میتوانید به صورت تعاملی چند ورودی را آزمایش کنید تا بررسی کنید که آیا درست کار میکند یا خیر. پس از تست منوال برای اطمینان از کارکرد کد میتوانید با خیال راحتتری ادامه دهید. حتی ممکن است پس از مدتی، ممکن است نیاز باشد تا کد اصلی را تغییر دهید، پس لازم است ابتدا آزمایشات منوال را انجام دهید و سپس کار خود را ادامه دهید. درست است که این فرآیند تست منوال زمان زیادی را تلف میکند اما اگر همه موارد را آزمایش نکنید، یقنا در ادامه با مشکلات بسیاری مواجه خواهید شد.پس بهتر است تستهای منوال را بهعنوان تست واحد بنویسید تا بتوانید به سرعت آنها را باهر تغییر کد اجرا کنید.
مثلا اگر می خواهید process.py خود را آزمایش کنید. می توانید یک tests/test_process.py اضافه کنید:

و شروع به نوشتن تست های خود کنید. من معمولاً یک فایل در پوشه tests/ برای هر فایل در فهرست src/ با نام test_{module_name}.py ایجاد می کنم. چنین قانون نامگذاری به من اجازه میدهد تا هنگام ایجاد تغییرات در کدها، بدانم باید کدام فایل آزمایشی را اجرا کنم.
فریمورک های زیادی برای اجرای تست ها وجود دارد، اما من به شما توصیه می کنم از pytest استفاده کنید. به عنوان مثال، فرض کنید ما در حال نوشتن یک تابع برای تمیز کردن یک ستون حاوی نام هستیم و از آن در نوت بوک خود به شکل زیر استفاده می کنیم:
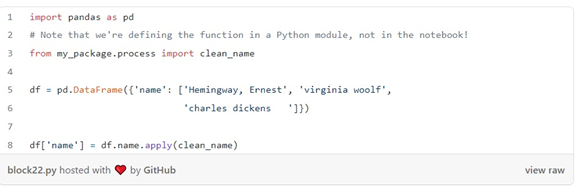
پس از کاوش در دادهها، متوجه میشویم که چه نوع پردازشی را برای پاک کردن نامها باید اعمال کنیم: کلمات را با حروف بزرگ بنویسیم، اگر نام در قالب “نام خانوادگی، نام” است، ترتیب را جابهجا کنیم، فضای خالی پیش یا پس را حذف کنیم و غیره. با چنین اطلاعاتی، می توانیم جفت (ورودی، خروجی) بنویسیم تا عملکرد خود را آزمایش کنیم:
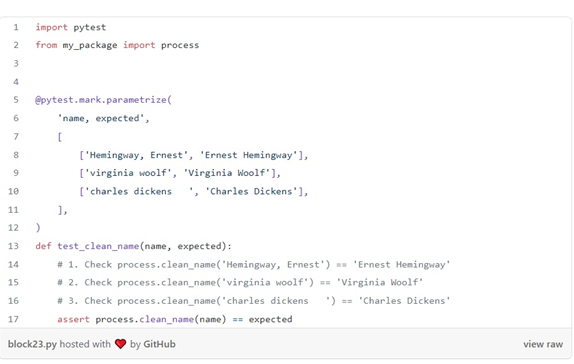
در اینجا ما از دکوراتور pytest.mark.parametrize برای پارامتری کردن یک تست برای هر جفت (name, expected) استفاده می کنیم. تابع clean_name خود را با نام فراخوانی می کنیم و بررسی می کنیم که آیا خروجی آن با مورد انتظار ما برابر است یا خیر.
سپس برای اجرای تست های خود:

نوشتن تستها کار بیاهمیت نیست، زیرا شامل فکر کردن به ورودیها و خروجیهای مناسب آنها است. اغلب، کد پردازش داده بر روی ساختارهای داده پیچیده مانند آرایه ها یا دیتا فریمها عمل می کند. توصیه من این است که در کوچکترین واحد داده ممکن، تست خود را انجام دهید. در مثال ما، تابع ما در value level عمل می کند. در موارد دیگر، شما ممکن است یک ترانسفورم را برای کل یک ستون و در پیچیده ترین حالت، به کل دیتا فریم اعمال کنید.
یادگیری نحوه استفاده از دیباگر پایتون یک مهارت عالی برای رفع خطاهای تست است. فرض کنید ما داریم روی تعمیر یک تست کار می کنیم. ما میتوانیم تستهای خود را دوباره اجرا کنیم، اما این بار هر زمان که یکی از آنها شکست بخورد، اجرا را متوقف کنیم:

در صورت شکست، یک سشن دیباگینگ تعاملی شروع می شود که می توانیم از آن برای دیباگینگ خط لوله خود استفاده کنیم. برای اطلاعات بیشتر در مورد دیباگر پایتون، این مستندات را بخوانید.
توجه داشته باشید که دستور قبلی یک سشن دیباگینگ را در هر خط مشخصی که خطایی ایجاد می کند، شروع می کند. اگر می خواهید دیباگر را از یک خط کد دلخواه شروع کنید، خط زیر را به آن اضافه کنید:
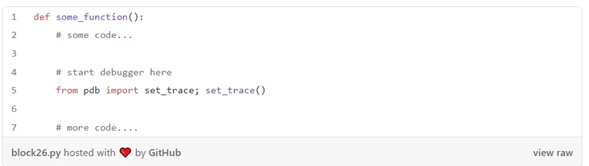
و تست های خود را به این صورت اجرا کنید:

پس از اتمام کار، from pdb import set_trace; set_trace() حذف کنید. اگر به جای دیباگر، می خواهید یک جلسه معمولی پایتون را در هر خط مشخصی شروع کنید:
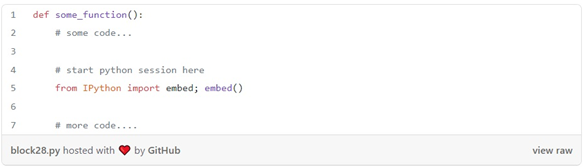
و تست های خود را به همین ترتیب فراخوانی کنید ( pytest tests/ -s)
سازماندهی سکشن ها
هنگام کاوش داده ها، طبیعی است که برای نوشتن کد به صورت ارگانیک در مورد آن اطلاعات بیشتری کسب کنیم. با این حال، مهم است که کد خود را دوباره مرور کنیم و پس از دستیابی به هر هدف کوچکی (مثلا ایجاد یک نمودار جدید) آن را دوباره سازماندهی کنیم. ارائه سازماندهی واضح به نوتبوکهایمان، درک آنها را آسانتر میکند. به عنوان یک قاعده کلی، من به شخصه نوت بوکهایم را با همان ساختار نگه می دارم:
- Import statements
- پیکربندی (به عنوان مثال، اتصالات پایگاه داده باز)
- بارگذاری داده ها
- محتوا
هر بخش محتوا یک ساختار استاندارد دارد:
- علامت گذاری هدر (
# My notebook section) - شرح. یک یا دو خط خلاصه ای از آنچه این بخش در مورد آن است
- akeaways. چند تیتر ازمهم ترین آموخته های این بخش
- کد. برنامه واقعی که داده ها را پاکسازی، تجزیه و تحلیل یا ترسیم می کند.
استفاده از یک خط کد
هنگام بازسازی کدهای قدیمی، ممکن است از پاکسازی کامل آن غافل شویم. برای مثال، فرض کنید از بستهای به نام some_plotting_package برای ایجاد نمودارهای سفارشی استفاده کردهایم، اما بعدا متوجه شدیم که آن چیزی نیست که به دنبال آن بودهایم. یا شاید ممکن است سلولهایی را که چنین بستهای را فراخوانی میکنند حذف کنیم، اما فراموش کنیم دستور import some_plotting_package را حذف کنیم. با نوشتن برنامه های گسترده تر، نادیده گرفتن این جزئیات کوچک آسانتر میشود. اگرچه ممکن است این مشکلات هیچ تأثیری بر اجرای برنامه نداشته باشند، اما یقینا تأثیر قابل توجهی بر خوانایی آن خواهند داشت.
اکثر ویرایشگرهای متن دارای پلاگین هایی هستند که مشکلات را شناسایی کرده و خطوط مشکل را علامت گذاری می کنند. در اینجا یک اسکرین شات از کد ویژوال استودیو وجود دارد که مشکلی را در خط اول نشان می دهد ( matplotlib وارد شده است اما استفاده نشده است):
متأسفانه، پلاگین های زیادی برای نوت بوکهای upyter notebook/lab وجود ندارد.حتی jupyterlab-flake8که به نظر می رسد مطمئن ترین گزینه باشد، پروژهای رها شده است.
من خودم بهترین روشی که برای لینت Lint نوتبوکهایم پیدا کردهام این است که از فایلهای .ipynb استفاده نکنم و از فایلهای .py استفاده کنم. jupytext یک پلاگین ژوپیتر را پیاده سازی می کند و به شما امکان می دهد فایل های .py را به عنوان نوت بوک باز کنید. برای مثال، فرض کنید که exploratory.ipynb دارید و میخواهید آن را پر کنید. ابتدا نوت بوک را با استفاده از jupytext به یک اسکریپت تبدیل کنید:

دستور بالا یک exploratory.py ایجاد می کند که همچنان می توانید آن را مانند یک نوت بوک باز کنید. اگر از jupyter notebook استفاده می کنید، این کار به طور خودکار اتفاق می افتد. اگر از jupyter lab استفاده می کنید، باید کلیک راست کنید -> Right Click -> Open With… -> Notebook
پس از ویرایش “نوت بوک” خود، می توانید آن را در هر ویرایشگر متنی که از لینتینگ linting پایتون پشتیبانی می کند باز کنید. من Visual Studio Code را توصیه میکنم زیرا راهاندازی آن برای Python linting رایگان و بسیار آسان است. توجه داشته باشید که گزینه های زیادی برای انتخاب وجود دارد اما توصیه من استفاده از flake8 است.
توجه داشته باشید که از آنجایی که فایلهای .py از ذخیره خروجی فایل پشتیبانی نمیکنند، اگر فایل خود را ببندید، همه جداول و نمودارها حذف میشوند. با این حال، میتوانید از ویژگی جفتسازی jupytext برای جفت کردن یک فایل .py با یک فایل .ipynb استفاده کنید. در این حالت در حالی که شما فایل .py را ویرایش می کنید، اما نوت بوک .ipynb برای پشتیبان گیری از خروجی شما استفاده می کند.
استفاده از یک فرمت کننده خودکار کد
لینترها فقط محل مشکلات را نشان می دهند اما آنها را برطرف نمی کنند. در حالی که فرمتکنندههای خودکار این کار را برای شما انجام میدهند و کد شما را خواناتر میکنند. پرکاربردترین فرمت کننده خودکار کد black است، اما گزینه های دیگری مانند yapf هم وجود دارد.
چند گزینه برای فرمت کردن خودکار فایلهای .ipynb وجود دارد (یک، دو، سه). من به شخصه هیچکدام از اینها را امتحان نکردهام، بنابراین نمی توانم در مورد استفاده آنها نظری بدهم. روش پیشنهادی من همانی است که در بخش قبل توضیح داده شد: از jupytext برای باز کردن فایلهای .py به عنوان نوتبوک استفاده کنید، سپس با استفاده از Visual Studio Code، قالببندی خودکار را برای آن فایلهای .py اعمال کنید. برای دستورالعمل های مربوط به تنظیم قالب بندی در VS Code اینجا را کلیک کنید.
توجه داشته باشید که فرمتکنندههای خودکار نیز همه مشکلاتی را که با flake8 شناسایی نمیشود را برطرف نمیکنند، بنابراین ممکن است همچنان به ویرایش دستی نیاز داشته باشید.
نوشتن نوتبوکهای کوتاه تر
از آنجایی که نوتبوکها به صورت تعاملی نوشته میشوند، ما اغلب تمایل داریم که نامهای متغیر کوتاه که طبق قراردادهای دیکته شده کتابخانههایی که از آنها استفاده میکنیم است را به کار ببریم. من خودم نیز بیشتر از آن چیزی که فکر کنید این اشتباه را کرده ام و چنین کاری را انجام داده ام:
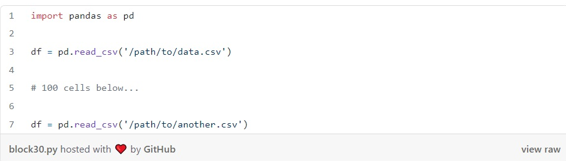
استفاده مجدد از نام متغیرها خود به تنهایی منبع مهمی از خطاها است. هنگام توسعه تعاملی، ممکن است بخواهیم چند keystrokes را ذخیره کنیم و نام های کوتاهی را به اکثر متغیرها اختصاص دهیم. این کار اگرچه به جستجوی سریع منجر میشود ، اما هر چه نوتبوکهای ما طولانیتر باشند، احتمال بروز مشکلات بیشتر میشود. بهترین روش این است که نوت بوک های خود را به قطعات کوچکتر تقسیم کنیم تا احتمال عوارض جانبی را کاهش دهیم.
شکستن نوتبوکها به چند قسمت آنقدرها هم که به نظر میرسد آسان نیست، زیرا باید نوتبوکهایی را به گونهای تقسیم کنیم که بتوانیم یک قطعه را به قسمت بعدی متصل کنیم (یعنی دیتا فریمهایمان را یکبار ذخیره کنیم و در قسمت بعدی مجدد بارگذاری کنیم).اینکار از آنجایی که کد قابل نگهداری بیشتری ایجاد میکند بسیار کمک کننده است.
تصمیمگیری در مورد اینکه چه زمانی خوب است که یک سلول جدید اضافه کنید و چه زمانی یک نوت بوک، امری بسیار ذهنی است، اما من یک سری قوانین سرانگشتی برای خود دارم که به این صورت است:
- مجموعه داده های مختلف باید در یک نوت بوک متفاوت باشد
- هنگام پیوستن به دیتا بیس، یک مجموعه جدید ایجاد کنید
- یک نوت بوک برای تمیز کردن داده ها، دیگری برای رسم (یا تولید ویژگی در صورت انجام ML)
البته این بستگی به پیچیدگی پروژه شما دارد. اگر با یک دیتا بیس کوچک کار می کنید، ممکن است منطقیتر باشد که همه چیز را در یک نوت بوک نگه دارید، اما در صورتی که با دو یا چند منبع داده کار می کنید، بهتر است آن را تقسیم کنید.
اگر میخواهید در زمان الحاق چندین نوتبوک به یک خط لوله صرفهجویی کنید، Ploomber را امتحان کنید. این برنامه نه تنها برای نوشتن نوتبوکهای کوتاه تر به شما کمک میکند، بلکه ویژگی های بسیار بیشتری مانند موازی سازی نوت بوک، ابزارهای دیباگینگ و اجرا در ابر نیز است.
کلام نهایی
نوشتن نوتبوکهای تمیز تلاش زیادی میطلبد، اما مطمئناً ارزش وقتی که برای آن صرف میکنید را دارد. چالش اصلی نوشتن کد تمیز، دستیابی به تعادل سالم بین سرعت تکرار و کیفیت کد است. ما باید به دنبال تعیین حداقل سطح کیفیت در کدهای خود باشیم و آن را به طور مداوم بهبود دهیم. با پیروی از این ده توصیه، میتوانید نوتبوکهای تمیزتری بنویسید که آزمایش و نگهداری از آنها آسانتر باشد.
آیا شما ایده دیگری در مورد بهبود کیفیت کد نوت بوک Jupyter داریدآن را با ما در میان بگذارید.






