
طی یک دهه اخیر، دستاوردهای مهمی در حوزه سنتز گفتار یا تبدیل متن به گفتار حاصل شده است که ریشه در پیشرفت شبکههای عصبی و مدلسازی انتها به انتها «End-to-End modeling» دارد. سال گذشته شرکت مایکروسافت، از مدل VALL-E رونمایی نمود که یک مدل زبان رمزگذاری عصبی «Neural codec language model» است و میتواند با داشتن تنها ۳ ثانیه از صدای ضبط شده هر گوینده یی، گفتار شخصی شده با کیفیت بالا و قابل قبول را تولید کند.
عملکرد این مدل، از سیستمهای پیشرفته تولید گفتار از متن «بدون پیش آموزش» در زمان خودش فراتر و بهتر بود.
در ادامه این پیشرفتها، در یک مقاله جدید با نام «VALL-E ۲: مدلهای زبان رمزگذاری عصبی در تراز عملکرد انسانی برای تولید گفتار از متن بدون پیش آموزش»، تیم پژوهشی مایکروسافت، VALL-E ۲ را به عنوان آخرین دستاورد در زمینه مدلهای زبان رمزگذاری عصبی معرفی نموده است.
این نوآوری یک نقطه عطف در تولید گفتار از متن بدون پیش آموزش محسوب میگردد، چرا که برای نخستین بار به سطح عملکرد انسانی دست یافته است.

VALL-E ۲ نسخه ارتقا یافته VALL-E است که از روش مدل سازی زبان رمزگذاری عصبی برای تولید گفتار استفاده میکند. این مدل دو ویژگی جدید مهم را معرفی مینماید: نمونه برداری آگاهانه از تکرارها و مدل سازی گروهی کدها.

نمونه برداری آگاهانه از تکرارها، پیشرفتی بر روش نمونه برداری تصادفی در VALL-E است که به صورت سازگار برای پیش بینی هر توکن در هر گام زمانی، یکی از روشهای نمونه برداری تصادفی یا هستهای را انتخاب میکند. این انتخاب بر پایه تکرار توکن در تاریخچه رمزگشایی صورت میگیرد که منجر به افزایش ثبات فرایند رمزگشایی و پیشگیری از ایجاد حلقه بیپایان در VALL-E میگردد.
مدلسازی گروهی کدها، کدهای رمزگذاری را به گروههایی تقسیم میکند که هر گروه در یک قاب منفرد در طول فرایند مدلسازی خودبازگشتی «AutoRegressive – AR» مدلسازی میشود. این رویکرد با کاهش طول توالی (دنباله)، نتیجه گیری را سرعت میبخشد و با حل مشکل مدلسازی متون طولانی، عملکرد را ارتقا میبخشد.
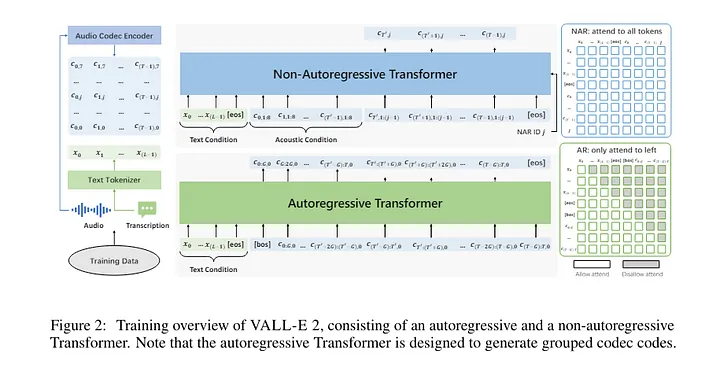
نکته جالب توجه این است که VALL-E ۲ صرفاً به دادههای ساده جفت گفتار-رونویسی برای آموزش نیاز دارد که این موضوع فرآیند جمع آوری و پردازش دادهها را به شدت ساده میسازد. این پیشرفت، امکان مقیاس پذیری بالقوه را فراهم میآورد و روند آموزش را تسهیل میبخشد.
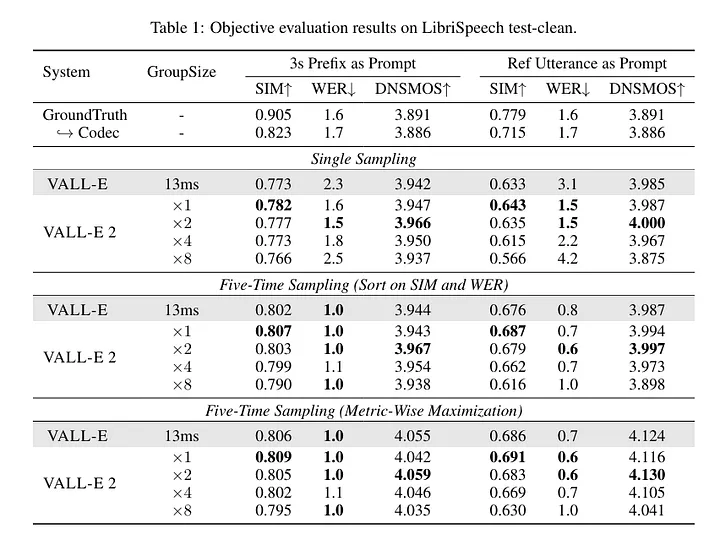
آزمایشهای انجام شده بر روی دادههای LibriSpeech و VCTK، نشان میدهد که VALL-E ۲ از لحاظ لحن گفتار، طبیعی بودن صدا و شباهت به گوینده اصلی، از سیستمهای قبلی پیشی گرفته است. این مدل، اولین مورد است که به تراز عملکرد انسانی در این معیارها دست یافته است. علاوه بر این، VALL-E ۲ به طور مداوم گفتار با کیفیت بالا را حتی برای جملاتی که پیچیده یا حاوی عبارات تکراری هستند، ترکیب میکند.
نمونههایی از عملکرد VALL-E ۲ در این صفحه قرار داده شده. همچنین مقاله VALL-E ۲: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers در آرشیو الکترونیکی arXiv نیز در دسترس میباشد که شما عزیزان در صورت تمایل میتوانید از لینکهای قرار داده شده جهت کسب اطلاعات بیشتر بهرهمند شوید.


