طبق سنت همیشگی، قبل از مطالعه مقاله پیشنهاد میکنیم با خواندن مقدمه آن خود را با آنچه پیش رو دارید به صورت فشرده آشنا کنید. این مقاله به بررسی اهمیت و تأثیر انتشار «Llama ۳.۱»، یک مدل زبانی بزرگ «LLM» متنباز توسط«Meta»، میپردازد. «Llama ۳٫۱» نماینده پیشرفتی قابل توجه در زمینه هوش مصنوعی است که دسترسی به فناوریهای پیشرفته «AI» را گسترش میدهد.
نکات کلیدی مقاله عبارتند از:
۱. «Llama ۳.۱» به عنوان یک نقطه عطف در توسعه هوش مصنوعی شناخته میشود.
۲. این مدل، فناوری «AI» قدرتمند را از انحصار شرکتهای بزرگ خارج کرده و در دسترس عموم قرار میدهد.
۳. با متنباز شدن این فناوری، امکان نوآوری و پیشرفت در حوزههای مختلف فراهم میشود.
۴. مدلهای «Llama» در پلتفرمهایی مانند «HuggingFace» و «llama. meta.com» در دسترس هستند.
۵. علیرغم محدودیتهای سختافزاری برای اجرای برخی مدلها (مانند مدل ۴۰۵ میلیارد پارامتری)، این پیشرفت یکی از مهمترین تحولات در حوزه مدلهای زبانی بزرگ محسوب میشود.
این مقاله اهمیت دموکراتیزه شدن (آزادسازی) فناوری هوش مصنوعی و تأثیر آن بر آینده تحقیقات و توسعه در این حوزه را برجسته میکند.
آنچه به نظر میرسد این است که چشمانداز هوش مصنوعی دستخوش تحولی چشمگیر شده است. امروزه، فناوری پیشرفته هوش مصنوعی دیگر در انحصار معدودی از شرکتهای قدرتمند نیست. به تعبیری این دوران جدید، عصر شکوفایی هوش مصنوعی منبع باز است که به همگان امکان دسترسی به مدلهای هوش مصنوعی قدرتمند، قابل سفارشیسازی و شفاف را میدهد. در این میان، شرکت متا با معرفی نوآورانه خانواده مدلهای زبانی بزرگ «Llama ۳.۱»، پیشگام این تحول عظیم شده است.
«Llama ۳.۱» پیشرفتی شگرف به ارمغان آورده است، این مدل با عملکردی برابر و حتی فراتر از غولهای هوش مصنوعی اختصاصی مانند «GPT-۴o» و «Claude ۳٫۵ Sonnet» ارائه شده است. این دستاورد از اهمیت فوقالعادهای برخوردار است.
در ادامه، به بررسی جزئیات این تحول میپردازیم:
- ۱. اهمیت منبع باز: از دیدگاه مارک زاکربرگ
- ۲. کاوش در معماری: ساختار داخلی «Llama ۳.۱»
- ۳. تعهد متا به مقیاسپذیری ایمنی هوش مصنوعی
- ۴. سنجش عملکرد «Llama ۳.۱»
- ۵. مقایسه لاما «Llama ۳.۱» با «Llama ۳»
- ۶. مقایسه «Llama ۳.۱» با ۴۰۵ میلیارد پارامتر در برابر سایر مدلهای پیشرفته
- ۷. نتیجهگیری
اهمیت منبع باز: از دیدگاه مارک زاکربرگ
بیایید پیش از پرداختن به «Llama ۳٫۱»، به موضوع مرتبط دیگری بپردازیم،البته کوتاه و در راستای مقاله. مارک زاکربرگ در نامهای به تشریح اهمیت هوش مصنوعی منبع باز پرداخته و بر مزایای عمیق این رویکرد برای توسعهدهندگان، متا و جهان تأکید کرده است. از نظر او، منبع باز به نفع همگان است:
مزایای منبع باز برای توسعهدهندگان:
۱. سفارشیسازی و کنترل:
توسعهدهندگان کنترل بیسابقهای بر مدلها به دست میآورند. این امر به آنها امکان میدهد مدلها را مطابق با نیازها و کاربردهای خاص خود تنظیم کنند. آنها میتوانند مدلها را روی مجموعه دادههای خود «ریزتنظیم» کنند، برای وظایف منحصر به فرد تطبیق دهند و در هر محیطی، از سرورهای ابری تا رایانههای محلی، پیادهسازی کنند.
اگر عبارت «ریز تنظیم» برایتان گنگ است باید بگویم که «ریزتنظیم» یا «fine-tuning» فرآیندی است که طی آن یک مدل هوش مصنوعی از پیش آموزش دیده، با استفاده از دادههای خاص یک وظیفه یا دامنه، مجدداً آموزش میبیند تا عملکرد آن برای آن وظیفه یا دامنه خاص بهبود یابد.
۲. امنیت و حریم خصوصی دادهها:
مدلهای منبع باز به توسعهدهندگان امکان کنترل کامل بر دادههای خود را میدهند. آنها میتوانند این مدلها را در محل خود پیادهسازی کنند و بدین ترتیب نیاز به اشتراکگذاری دادههای حساس با ارائهدهندگان شخص ثالث را از بین ببرند و حریم خصوصی دادهها را تضمین کنند.
۳. نوآوری از طریق همکاری:
منبع باز، اکوسیستمی از همکاری را ترویج میدهد که توسعه را از طریق به اشتراکگذاری دانش، مشارکتهای جامعه و ظهور ابزارها و بهینهسازیهای تخصصی تسریع میکند.
مزایای منبع باز برای متا:
۱. اجتناب از وابستگی به فروشنده:
متا، همانند سایر شرکتها، از آزادی انتخاب و تطبیق ابزارهای هوش مصنوعی خود بدون وابستگی به ارائهدهندگان منبع بسته بهرهمند میشود. منبع باز، دسترسی بلندمدت به بهترین فناوری را بدون محدودیت تضمین میکند.
۲. پرورش یک اکوسیستم قوی:
انتشار مدلهای منبع باز، توسعه اکوسیستمی غنی از ابزارها، بهینهسازیها و یکپارچهسازیها را تسریع میکند که مستقیماً به محصولات و خدمات خود متا نیز سود میرساند.
مزایای منبع باز برای جهان:
۱. دموکراتیزه کردن دسترسی به هوش مصنوعی:
هوش مصنوعی منبع باز موانع را از بین میبرد و فناوری قدرتمند را برای طیف گستردهتری از افراد، سازمانها و کشورها، صرف نظر از منابع یا تخصص فنی آنها، در دسترس قرار میدهد و فرصتهای اقتصادی ایجاد میکند.
۲. افزایش ایمنی و امنیت:
شفافیت در توسعه هوش مصنوعی بسیار مهم است. مدلهای منبع باز امکان بررسی دقیقتر توسط جامعه را فراهم میکنند و شناسایی و کاهش خطرات بالقوه را تسریع میبخشند. این رویکرد مشارکتی در راستای ایمنی، به نفع همگان است.
۳. ترویج همکاری جهانی:
هوش مصنوعی منبع باز روحیه همکاری و به اشتراکگذاری دانش را تقویت میکند و همچنین پیشرفت تحقیق و توسعه هوش مصنوعی را از طریق تلاشهای جمعی تسریع میکند.
لازم به ذکر است که این دیدگاه زاکربرگ است و ممکن است افراد دیگر نظرات متفاوتی داشته باشند.
کاوش در معماری: ساختار درونی «Llama ۳.۱»
قدرت «Llama ۳.۱» از معماری ترانسفورمر آن که به دقت بهینهشده است نشأت میگیرد. این معماری که به طور ویژه برای مدلسازی زبان خودکار طراحی شده، به مدل امکان میدهد متن را با روانی و انسجام قابل توجهی درک و تولید کند. در ادامه، عناصر کلیدی که عملکرد «Llama ۳٫۱» را شکل میدهند، بررسی میکنیم:
آشناسازی «embeddings»: تبدیل متن به معنا
فرایند با تبدیل متن ورودی به نمایشهای عددی موسوم به آشناسازی «embeddings» آغاز میشود. این آشناسازیها صرفاً کدهای عددی نیستند؛ بلکه معنای معنایی کلمات، روابط آنها با یکدیگر و ظرافتهای زمینهای را ثبت میکنند.
منظور اصلی این بخش این است که در مرحله اول پردازش متن، متن ورودی باید به نمایشهای عددی به نام «embeddings» تبدیل شود. این «embeddings»، نه صرفا کدهای عددی خشک و بیمعنی هستند، بلکه قادرند معنای معنایی کلمات، ارتباطات آنها با یکدیگر و همچنین جزئیات و ظرایف معنایی مربوط به بافت و موقعیت استفاده از آنها را به خوبی منعکس کنند.
به عبارت دیگر، این «embeddings» قرار است متن را به فرمی عددی تبدیل کنند که بتواند معنا و مفهوم کلمات و روابط بین آنها را نشان دهد، نه صرفاً آنها را به کدهای عددی خام تبدیل کند. این گام اولیه و مهم در پردازش متن برای استفاده در سیستمهای یادگیری ماشین است.
دسته رمزگشا «Decoder Stack»: موتور محرک فهم و درک
پشته رمزگشا، قلب مدل است که از چندین لایه بلوکهای ترانسفورمر تشکیل شده است. هر بلوک نقشی حیاتی در پردازش و درک متن تعبیه شده ایفا میکند:
- لایه توجه به خود «Self-Attention Layer»:
این لایه به مدل اجازه میدهد همزمان بر قسمتهای مختلف توالی ورودی، تمرکز کند و وابستگیهای بین کلمات، عبارات و حتی قطعات طولانیتر را ثبت نماید. این فرآیند مانند گفتگویی درونی است که در آن بخشهای مختلف مغز ارتباط برقرار کرده و متن ورودی را از دیدگاههای متفاوت تحلیل میکنند.
- شبکه عصبی پیشخور «Feedforward Neural Network»:
این لایه، اطلاعات دریافتی از لایه «توجه به خود» را بیشتر پردازش میکند، الگوها را شناسایی نموده، ویژگیهای معنادار را استخراج کرده و درک مدل از متن را پالایش میکند. عملکرد این لایه مشابه یک فیلتر پیچیده است که اطلاعات را غربال کرده و مهمترین عناصر را برجسته میسازد.
لایه خروجی «Output Layer»: تولید متن معنادار
لایه خروجی نهایی، اطلاعات پردازش شده از «دسته رمزگشا» را به یک توزیع احتمال بر روی واژگان مدل تبدیل میکند. این توزیع نشاندهنده احتمال ظهور هر کلمه در ادامه توالی است و به مدل امکان میدهد توکن بعدی را پیشبینی کرده یا متنی منسجم و متناسب با زمینه تولید نماید.
تغییرات معماری در «Llama ۳.۱»:
«Llama ۳.۱» بر روی معماری پایهای ساخته شده و چندین تغییر کلیدی را برای بهبود عملکرد و قابلیتهای خود ادغام کرده است:
«توجه گروهی به پرسشها» «GQA – Grouped Query Attention»:
این نوآوری، سرعت نتیجه گیری را بهبود بخشیده و نیازهای حافظه را با گروهبندی چندین سر توجه در کنار هم کاهش میدهد. این امر به مدل اجازه میدهد اطلاعات را هم در حین آموزش و هم در زمان نتیجه گیری، کارآمدتر پردازش کند.
تکنیک محدود کردن توجه بین اسناد مختلف:
برای مدیریت توالیهای طولانی حاوی چندین سند، «Llama ۳٫۱» یک تکنیک محدود کردن توجه معرفی میکند. این تکنیک از ایجاد «توجه-به-خود» بین توکنهای متعلق به اسناد مختلف جلوگیری کرده و اطمینان حاصل میکند که مدل بر روابط درون-سندی تمرکز کرده و اتصالات اشتباهی ایجاد نکند.
واژگان گسترش یافته:
«Llama ۳.۱» دارای واژگان گسترش یافتهای با ۱۲۸٬۰۰۰ توکن است که به آن امکان میدهد طیف گستردهتری از عناصر زبانی، از جمله نمادهای تخصصی، قطعات کد و نمادهای ریاضی را مدیریت کند. این گسترش به طور قابل توجهی توانایی مدل را در درک و تولید محتوای متنی متنوع و تخصصی ارتقا میبخشد.
تنظیم ابر پارامتر «RoPE»:
برای پشتیبانی بهتر از پنجرههای زمینه طولانیتر، Llama ۳.۱ ابرپارامتر «Rotary Position Embeddings – RoPE» را تنظیم میکند. این اصلاح، این تغییر توانایی مدل برای درک وابستگیهای بلندمدت در متن را تقویت میکند که برای وظایفی که نیاز به درک دنبالههای متنی گسترده دارند، حیاتی است.
این بهبودهای معماری به عملکرد استثنایی Llama ۳٫۱ کمک میکند و به آن امکان میدهد وظایف پیچیده زبانی را انجام دهد، از پنجرههای زمینه گسترده پشتیبانی کند و اطلاعات را به طور کارآمد پردازش نماید.
مدیریت متا در ایمنی هوش مصنوعی
همانطور که مدلهای هوش مصنوعی قدرتمندتر میشوند، تأثیر بالقوه آنها بر جامعه نیز افزایش مییابد. متا اهمیت توسعه و استقرار مسئولانه هوش مصنوعی را به رسمیت شناخته و رویکرد پیشگیرانهای را در زمینه ایمنی در تمام مراحل توسعه «Llama ۳٫۱» اتخاذ کرده است:
ایجاد ایمنی از پایه: گردآوری و فیلتر کردن دادهها
پایه و اساس هوش مصنوعی ایمن در دادههایی است که برای آموزش مدلها استفاده میشود. متا تکنیکهای فیلتر سختگیرانهای را در طول گردآوری دادهها اعمال میکند تا محتوایی که ممکن است منجر به خروجیهای مضر یا ناایمن شود، حذف شود. این شامل موارد زیر است:
شناسایی و حذف محتوای مضر: مجموعه دادهها به دقت برای یافتن و حذف محتوای نفرتپراکنی، خشونت، تبعیض و سایر اشکال محتوای مضر اسکن میشوند.
کاهش سوگیری: تلاشهایی برای کاهش سوگیریها بر اساس جنسیت، نژاد، مذهب یا سایر ویژگیهای حساس انجام میشود تا خروجیهای مدل منصفانه و فراگیر باشند.
حفاظت از حریم خصوصی: اطلاعات شناسایی شخصی «PII» به دقت از مجموعه دادهها حذف میشود تا حریم خصوصی افراد حفظ شود و از سوءاستفاده احتمالی جلوگیری شود.
هدایت مدل به سمت ایمنی: ریزتنظیم برای رفتار مسئولانه
فراتر از گردآوری دادهها، متا از تکنیکهای ریز تنظیم تخصصی استفاده میکند تا ملاحظات ایمنی را در خود مدل نهادینه کند. این شامل موارد زیر است:
مجموعه دادههای مخصوص ایمنی: «Llama ۳.۱» بر روی مجموعه دادههای طراحی شده بهطور خاص برای آموزش آن در جهت اجتناب از تولید محتوای ناایمن یا مضر ریزتنظیم میشود. این مجموعه دادهها شامل مثالهایی از پیشفرضهای مضر و بیضرر است که به مدل امکان میدهد بین پاسخهای قابل قبول و غیرقابل قبول تمایز قائل شود.
یادگیری تقویتی با بازخورد انسانی «RLHF»: این تکنیک بازخورد انسانی را در فرآیند آموزش ادغام میکند، به مدل امکان میدهد از ترجیحات انسان برای رفتار ایمن و اخلاقی یاد بگیرد. ارزیابان پاسخهای مدل را ارزیابی کرده و بازخورد ارائه میدهند، که پس از آن برای تکمیل فرآیند تصمیمگیری مدل استفاده میشود.
ایجاد حفاظهای سیستمی: اقدامات ایمنی در سطح سیستم
«Meta» با توسعه و انتشار ابزارهای ایمنی در سطح سیستم که به عنوان درگاههای محافظ عمل میکنند از ورودیها و خروجیهای مضر جلوگیری میکنند.
«Llama Guard ۳»: این طبقهبندی کننده ایمنی پیشرفته طراحی شده است تا طیف گستردهای از محتوای بالقوه مضر را در هر دو ورودی پیشفرض و خروجیهای مدل تشخیص دهد. از چندین زبان پشتیبانی میکند، پنجرههای زمانی طولانی را مدیریت میکند و به طور خاص برای شناسایی تهدیدها و خطرات نوظهور آموزش دیده است.
«Prompt Guard»: این ابزار بر روی حملات تزریق سریع متمرکز است، جایی که کاربران سودجو سعی در دور زدن رفتار مورد نظر مدل با ایجاد پیشفرضهای متخاصمانه دارند. محافظ پیشفرض به توسعهدهندگان کمک میکند تا این حملات را شناسایی و مسدود کنند، تا مدل در مسیر خود باقی بماند.
شناسایی پیشگیرانه آسیبپذیریها: تیم قرمز و آزمایش ارتقا
متا منتظر بروز مشکلات نمیماند؛ آنها به طور فعال به دنبال آنها میگردند. تیمهای قرمز اختصاصی، متشکل از متخصصان در زمینههای «امنیت سایبری» «cybersecurity»، «یادگیری ماشین خصمانه» «adversarial machine learning»، «هوش مصنوعی مسئولانه» «responsible AI» و «نظارت بر محتوا» «content moderation»، آزمایشهای دقیقی را برای کشف آسیبپذیریها و ارزیابی خطرات احتمالی انجام میدهند:
تیم قرمز «Red Teaming»: این تیمها از طیف گستردهای از تکنیکها از جمله «پرسش خصمانه» «adversarial prompting» استفاده میکنند تا راههای غیرمنتظره سوءاستفاده یا بهرهبرداری از مدل را شناسایی کنند. آنها مدل را به حد اکثر ظرفیت خود میرسانند، تلاش میکنند خروجیهای مضر یا ناایمن را به دست آورند و از یافتههای خود برای تدوین استراتژیهای کاهش خطر استفاده میکنند.
آزمایش ارتقا «Uplift Testing»: متا آزمایش ارتقا را انجام میدهد تا بسنجد آیا استفاده از «Llama ۳٫۱» به طور معناداری احتمال فعالیتهای مضر را در مقایسه با فناوریهای موجود افزایش میدهد یا خیر. به عنوان مثال، آنها ارزیابی میکنند که آیا مدل به طور قابل توجهی توانایی تولید «حملات فیشینگ هدفمند» «spear-phishing attacks» دارد یا خیر و یا میتواند فرایند برنامهریزی حملات سلاحهای شیمیایی و بیولوژیکی را افزایش میدهد یا خیر.
راهنمای توسعه مسئولانه: راهنمای استفاده مسئولانه
متا تشخیص میدهد که ساخت هوش مصنوعی ایمن یک مسئولیت مشترک است. آنها یک «راهنمای استفاده مسئولانه» «Responsible Use Guide» جامع منتشر میکنند تا بهترین شیوهها را برای استقرار مسئولانه «Llama ۳٫۱» در اختیار توسعهدهندگان قرار دهند. این راهنما شامل ملاحظات کلیدی از جمله موارد زیر است:
«حریم خصوصی و امنیت دادهها» «Data Privacy and Security»: محافظت از دادههای کاربر و اطمینان از مدیریت امن آن.
«عدالت و فراگیری» «Fairness and Inclusivity»: کاهش تعصبات و ترویج توسعه هوش مصنوعی فراگیر.
«شفافیت و پاسخگویی» «Transparency and Accountability»: مستندسازی فرآیندهای توسعه و شفافسازی محدودیتهای مدل.
«آزمایش ایمنی و کاهش خطر» «Safety Testing and Mitigation»: انجام آزمایشهای دقیق ایمنی و پیادهسازی تدابیر ایمنی مناسب.
سنجش عملکرد «Llama ۳.۱»
به نظر شما «Llama ۳.۱» واقعاً در مقایسه با نسخه قبلی خود، «Llama ۳٫۱»، و غولهای صنعت مانند «GPT-۴» و «Claude» چگونه عمل میکند؟ برای درک بهتر این موضوع و همچنین درک کامل مقایسه صورت گرفته نیاز است برخی اصطلاحات و عبارات را قبل از مطالعه جدول (جدول مقایسه) بدانیم.
در اینجا دستهبندی برخی از معیارهای سنجش مورد استفاده آمده است:
دانش عمومی و پیروی از دستورالعمل:
«MMLU – Massive Multitask Language Understanding»: دانش عمومی را در ۵۷ وظیفه مختلف میسنجد.
«MMLU-Pro»: نسخه ارتقا یافته «MMLU» تقویت شده با سوالات چالشبرانگیز استدلالی.
«IFEval – Instruction Following Evaluation» (ارزیابی پیروی از دستورالعمل): توانایی پیروی از دستورالعملهای زبان طبیعی را ارزیابی میکند.
معیارهای سنجش کدنویسی:
«HumanEval»: تولید کد کاربردی پایتون از توضیحات زبان طبیعی را ارزیابی میکند.
«MBPP – Mostly Basic Python Problems»: مهارت در حل مسائل کدنویسی پایتون در دنیای واقعی را آزمایش میکند.
معیارهای سنجش ریاضی و استدلال:
«GSM8K – Grade School Math 8K»: توانایی حل مسائل کلامی ریاضی در سطح دبستان را آزمایش میکند.
«MATH»: بر مسائل پیچیده ریاضی و مفاهیم پیشرفته تمرکز دارد.
«GPQA – Google-Proof Question Answering» پاسخگویی به سؤالات اثباتشده گوگل: مدل را با سؤالات دشوار مبتنی بر استدلال به چالش میکشد.
«ARC-Challenge – AI2 Reasoning Challenge»: بر استدلال عقل سلیم و درک اطلاعات ضمنی تمرکز دارد.
معیارهای سنجش استفاده از ابزار:
«Nexus»: توانایی تعامل با APIهای خارجی برای بازیابی اطلاعات و انجام اقدامات را ارزیابی میکند.
«BFCL – Berkeley Function Calling Leaderboard» جدول ردهبندی فراخوانی تابع برکلی: ارزیابی جامعی از قابلیتهای فراخوانی تابع ارائه میدهد.
معیارهای سنجش متن طولانی:
«ZeroSCROLLS»: درک و توانایی پاسخگویی به سؤالات در مورد اسناد طولانی را ارزیابی میکند.
«NIH – Needle-in-a-Haystack» سوزن در انبار کاه: توانایی یافتن اطلاعات خاص در توالیهای متنی بسیار طولانی را آزمایش میکند.
«InfiniteBench»: مدل را با وظایفی که نیاز به درک وابستگیهای دامنه طولانی در متن دارند، به چالش میکشد.
معیارهای سنجش چندزبانه:
«MGSM – Multilingual Grade School Math» (ریاضیات دبستان چندزبانه): توانایی حل مسائل کلامی ریاضی به چندین زبان را ارزیابی میکند.
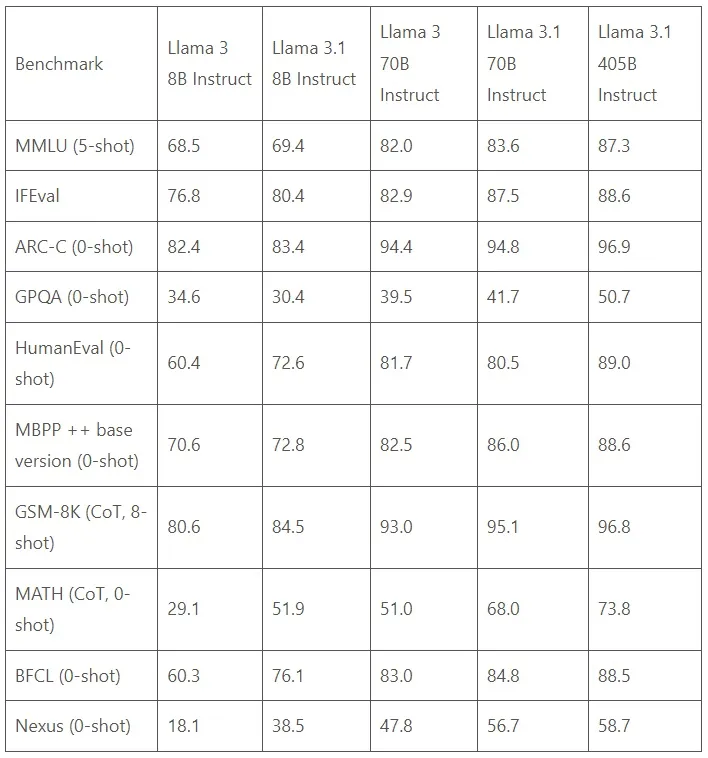
«Llama ۳.۱» در مقابل «Llama ۳»
در مقایسه با «Llama ۳»، مدل «Llama ۳.۱» طول متن را افزایش میدهد و از ۸ هزار «توکن» «token» به ۱۲۸ هزار میرسد، پشتیبانی چند زبانه را بهبود میبخشد، استفاده از ابزار را پیشرفت میدهد، تواناییهای استدلال را بهبود میبخشد، «تنظیم دستورالعمل» «instruction tuning» را پالایش میکند و اقدامات ایمنی را ارتقا میدهد.
«Llama ۳٫۱» در هر معیار سنجش به طور مداوم عملکرد بهتری نسبت به «Llama ۳» نشان میدهد، به ویژه در مدلهای تنظیم شده با دستورالعمل خاص، به جدول توجه کنید.
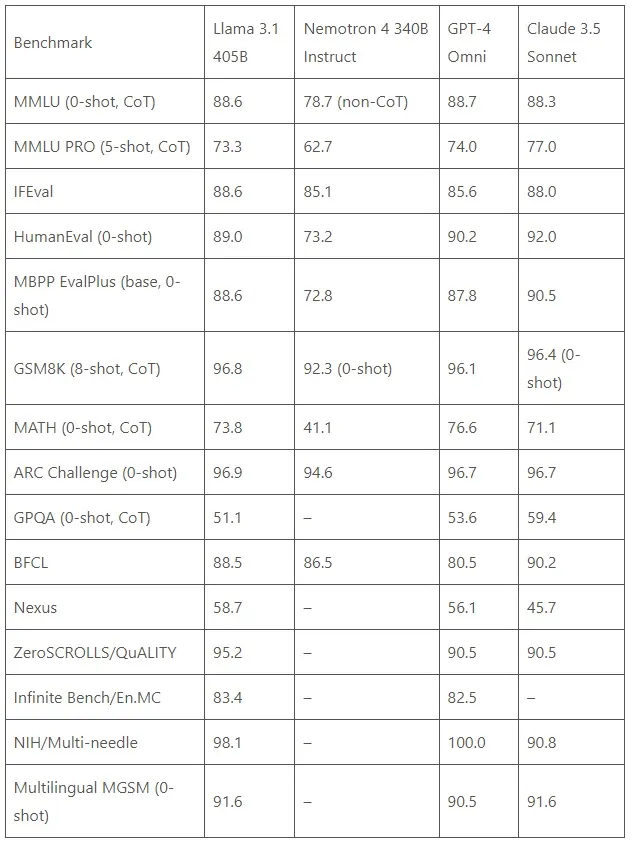
«Llama ۳.۱ ۴۰۵B» در مقابل غولها
هنگام مقایسه مستقیم با دیگر مدلهای پیشرو، «Llama ۳.۱ ۴۰۵B» به طور مداوم عملکردی مشابه یا بهتر از «GPT-۴» و «Claude ۳٫۵ Sonnet» در طیف متنوعی از وظایف نشان میدهد و خود را به عنوان یک مدل پیشرو و مدعی در این زمینه معرفی میکند.
این مدل در اکثر معیارهای سنجش، عملکرد بسیار بهتری نسبت به «Nemotron ۴ ۳۴۰B Instruct» نشان میدهد که پیشرفتهای معماری و روش آموزشی «Llama ۳.۱» را به نمایش میگذارد.
این سطح از عملکرد از یک مدل «منبع باز» «open-source» بیسابقه است!!!
نتیجهگیری
انتشار «Llama ۳.۱» نقطه عطفی در مسیر هوش مصنوعی به شمار میرود، زیرا نویدبخش آیندهای است که در آن فناوری قدرتمند هوش مصنوعی دیگر محدود به دیوارهای شرکتها نیست، بلکه در دسترس همگان قرار دارد. این انقلاب، توسعهدهندگان، پژوهشگران و سازمانهایی در هر اندازه را قادر میسازد تا از پتانسیل هوش مصنوعی بهرهمند شوند و نوآوری و پیشرفت را در حوزههای متعدد پیش ببرند.
این مدلها اکنون در «HuggingFace» و «llama.meta.com» در دسترس هستند.






