
جما ۲ «Gemma ۲» جدیدترین نسخه از سری مدلهای زبانی بزرگ و منبع باز گوگل است. این مدل در دو مقیاس مختلف عرضه شده است: یکی با ۹ میلیارد پارامتر و دیگری با ۲۷ میلیارد پارامتر. که هر کدام از این مدلها در دو نسخه ارائه شدهاند: نسخه پایه (که از قبل آموزش دیده) و نسخه بهینهشده بر اساس دستورالعملها. جما بر اساس مدل جمینی (Gemini) گوگل دیپمایند (Google Deepmind) ساخته شده و میتواند ۸ هزار توکن را در یک زمان پردازش کند.
چهار مدل برای جما ۲ وجود دارد که عبارتند از:
- ۱. Gemma-2-9b: مدل پایه ۹ میلیارد پارامتری
- ۲. Gemma-2-9b-it: نسخه بهینهشده بر اساس دستورالعملها از مدل پایه ۹ میلیارد پارامتری
- ۳. Gemma-2-27b: مدل پایه ۲۷ میلیارد پارامتری
- ۴. Gemma-2-27b-it: نسخه بهینهشده بر اساس دستورالعملها از مدل پایه ۲۷ میلیارد پارامتری
مدلهای جما ۲ با حجم دادهای تقریباً دو برابر نسخه قبلی خود آموزش دیدهاند. مدل ۲۷ میلیارد پارامتری با ۱۳ تریلیون توکن و مدل ۹ میلیارد پارامتری با ۸ تریلیون توکن آموزش دیدهاند. این دادهها عمدتاً شامل متون وب (بیشتر به زبان انگلیسی)، کد برنامهنویسی و فرمولهای ریاضیات بودهاند. اگرچه جزئیات دقیقی از ترکیب دادههای آموزشی مشخص نیست، اما میتوان حدس زد که حجم بیشتر دادهها و دقت بالاتر در انتخاب آنها، نقش مهمی در بهبود عملکرد این مدلها داشته است.
جما ۲ از همان مجوز نسخه قبلی استفاده میکند. این مجوز اجازه توزیع مجدد، بهینهسازی، استفاده تجاری و ایجاد نسخههای مشتق شده را میدهد.
پیشرفتهای فنی در جما ۲
جما ۲ شباهتهای زیادی با نسخه اول خود دارد. این مدل میتواند ۸۱۹۲ توکن را در یک زمان پردازش کند و از روش جاسازی موقعیت چرخشی «RoPE» استفاده میکند. چهار پیشرفت اصلی در جما ۲ نسبت به نسخه اصلی عبارتند از:
۱. اعلان پنجرهای (Sliding Window Attention): این تکنیک ترکیبی از مکانیزم پنجره اعلان کشویی و اعلان کامل را برای بهبود کیفیت تولید متن به کار میگیرد.
۲. محدودسازی ملایم خروجیها (Logit Soft-capping): این روش از افزایش بیش از حد مقادیر خروجی (لوجیتها) جلوگیری میکند و آنها را در یک محدوده مشخص مقیاسبندی میکند، که باعث بهبود فرآیند آموزش میشود.
۳. انتقال دانش (Knowledge Distillation): در این تکنیک، از یک مدل بزرگتر به عنوان «معلم» برای انتقال دانش به یک مدل کوچکتر استفاده میشود (این روش برای مدل ۹ میلیارد پارامتری به کار رفته است).
۴. ادغام مدلها (Model Merging): این تکنیک دو یا چند مدل زبانی بزرگ را در یک مدل جدید ترکیب میکند.
جما ۲ روی زیرساخت ابری گوگل و با استفاده از واحدهای پردازش تنسور (TPU) آموزش دیده است (مدل ۲۷ میلیارد پارامتری روی نسخه v۵p و مدل ۹ میلیارد پارامتری روی TPU v۴). برای این کار از چارچوبهای JAX و ML Pathways استفاده شده است.
نسخه دستورالعملمحور جما ۲ برای کاربردهای گفتمانی بهینه شده است. این نسخه با استفاده از ترکیبی از جفتهای پرسش و پاسخ مصنوعی و تولید شده توسط انسان آموزش دیده است. روشهای مورد استفاده شامل:
- تنظیم دقیق تحت نظارت (Supervised Fine-Tuning یا SFT)
- انتقال دانش از یک مدل بزرگتر
- یادگیری مضاعف با بازخورد انسانی (Reinforcement Learning from Human Feedback یا RLHF) با استفاده از یک مدل اضافی که بیشتر برای قابلیتهای مکالمهای طراحی شده است
- ادغام مدلها با استفاده از روش WARP برای بهبود عملکرد کلی
مشابه با مرحله پیشآموزش، جزئیاتی درباره مجموعه دادههای استفاده شده برای تنظیم دقیق یا پارامترهای مربوط به SFT و RLHF منتشر نشده است.
اعلان پنجرهای
پنجره اعلان کشویی روشی است که برای کاهش نیازهای حافظه و زمان محاسبات در مدلهای ترانسفورمر استفاده میشود. این روش در مدلهایی مانند میسترال نیز به کار رفته است. نوآوری جما ۲ در این است که یک اعلان پنجرهای به صورت کشویی روی هر لایه اعمال میکند (محلی – ۴۰۹۶ توکن)، در حالی که لایههای بین آنها همچنان از روش اعلان کامل استفاده میکنند (۸۱۹۲ توکن). احتمالاً این روش برای افزایش کیفیت در موقعیتهای با متن طولانی طراحی شده است.
محدودسازی ملایم
محدودسازی ملایم تکنیکی است که از رشد بیش از حد خروجیها (لوجیتها) جلوگیری میکند، بدون اینکه آنها را کاملاً قطع کند. این روش با تقسیم خروجیها بر یک مقدار آستانه بالایی (soft_cap) کار میکند، سپس آنها را از یک لایه tanh عبور میدهد (تا در محدوده (-۱، ۱) قرار گیرند)، و در نهایت دوباره در آستانه ضرب میکند. این کار تضمین میکند که مقادیر نهایی در بازه (-soft_cap، +soft_cap) قرار میگیرند، بدون اینکه اطلاعات زیادی از دست داده شود و در عین حال رسیدن به پایداری در فرآیند آموزش.
به طور خلاصه، خروجیها به این صورت محاسبه میشوند:
خروجی ← soft_cap * tanh (خروجی/soft_cap)
جما ۲ از محدودسازی ملایم برای لایه نهایی و برای هر لایه اعلان (attention layer) استفاده میکند. خروجیهای اعلانها در ۵۰٫۰ و خروجیهای نهایی در ۳۰٫۰ محدود میشوند.
در زمان انتشار، محدودسازی ملایم با Flash Attention / (Self-Debiasing Prompting Approach) SDPA سازگار نیست، اما هنوز میتوان از آنها در مرحله نتیجه گیری برای حداکثر کارایی استفاده کرد. تیم جما ۲ تفاوتهای بسیار جزئی را هنگام حذف محدودسازی ملایم در مرحله نتیجه گیری مشاهده کرده است.
بسیار خوب، من این بخش را نیز به زبان ساده و قابل فهم برای دانشجویان تازهکار رشتههای کامپیوتر و فناوری اطلاعات ترجمه میکنم:
انتقال دانش
انتقال دانش روشی محبوب برای آموزش یک مدل کوچکتر (دانشآموز) است تا رفتار یک مدل بزرگتر و قویتر (معلم) را تقلید کند. این کار با افزودن توزیع احتمالات توکنی از مدل معلم مثل GPT-4، Claude یا Gemini به وسیله پیشبینی توکن بعدی در مدلهای زبانی بزرگ انجام میشود. این روش مسیر بهتری را برای یادگیری مدل دانشآموز فراهم میکند.
طبق گزارش فنی جما ۲، انتقال دانش برای پیشآموزش مدل ۹ میلیارد پارامتری استفاده شده، در حالی که مدل ۲۷ میلیارد پارامتری از ابتدا آموزش دیده است.
برای مرحله پس از آموزش، تیم جما ۲ مجموعهای متنوع از مکملها را توسط یک مدل معلم (که در گزارش مشخص نشده، اما احتمالاً Gemini Ultra بوده) تولید کرده و سپس مدلهای دانشآموز را با استفاده از تنظیم دقیق تحت نظارت (SFT) روی این دادههای مصنوعی آموزش دادهاند. این روش اساس بسیاری از مدلهای باز مانند Zephyr و OpenHermes است که کاملاً روی دادههای مصنوعی از مدلهای زبانی بزرگتر آموزش دیدهاند.
اگرچه این روش موثر است، اما معایبی هم دارد. تفاوت ظرفیت بین مدل دانشآموز و معلم میتواند منجر به عدم تطابق بین مرحله آموزش و مرحله نتیجه گیری شود، جایی که متن تولید شده توسط مدل دانشآموز در هنگام نتیجه نهایی، خارج از محدوده متنهایی است که در طول آموزش ارائه شده است.
برای حل این مشکل، تیم جما ۲ از روش «انتقال دانش محوری» استفاده کرده است. در این روش، مدل دانشآموز مکملهایی را با استفاده از دستورالعملهای SFT تولید میکند. سپس از این مکملها برای محاسبه واگرایی KL بین خروجیهای مدل معلم و دانشآموز استفاده میشود. با کمینه کردن این واگرایی در طول آموزش، مدل دانشآموز یاد میگیرد که رفتار معلم را به طور دقیق مدل کند و در عین حال عدم تطابق بین مرحله آموزش و مرحله نتیجه گیری را به حداقل برساند.
این رویکرد بسیار جالب است، زیرا در جامعه مشاهده کردهایم که روشهای محوری مانند online DPO مدلهای قویتری تولید میکنند. یکی از مزایای انتقال دانش محوری این است که شما فقط به خروجیهای مدل معلم نیاز دارید و نیازی به استفاده از مدلهای اضافه یا استفاده از مدلهای زبانی بزرگ به عنوان داور برای بهبود مدل ندارید. جالب خواهد بود که ببینیم آیا این روش در ماههای آینده در میان تنظیمکنندگان دقیق محبوبتر میشود یا خیر!
ادغام مدل ها
ادغام مدل یک تکنیک نسبتاً جدید و آزمایشی است که دو یا چند مدل زبانی بزرگ را با هم ترکیب میکند تا یک مدل جدید ایجاد کند. این روش بدون نیاز به شتابدهندههای خاص قابل استفاده است. Mergekit یک ابزار محبوب متنباز برای ادغام مدلهای زبانی بزرگ است که روشهای مختلفی مانند خطی، SLERP، TIES و DARE را پیادهسازی میکند.
طبق گزارش فنی، جما ۲ از یک تکنیک جدید به نام Warp استفاده کرده که مدلها را در سه مرحله متمایز ادغام میکند:
۱. میانگین متحرک نمایی (EMA – Exponential Moving Average): این روش در طول فرآیند تنظیم دقیق یادگیری مضاعف (RL) اعمال میشود.
۲. درونیابی خطی کروی (SLERP – Spherical Linear intERPolation): این مرحله پس از تنظیم دقیق RL محوری اعمال میشود.
۳. درونیابی خطی به سمت مقداردهی اولیه (LITI – Linear Interpolation Towards Initialization): این مرحله پس از مرحله SLERP اعمال میشود.
ارزیابی جما ۲
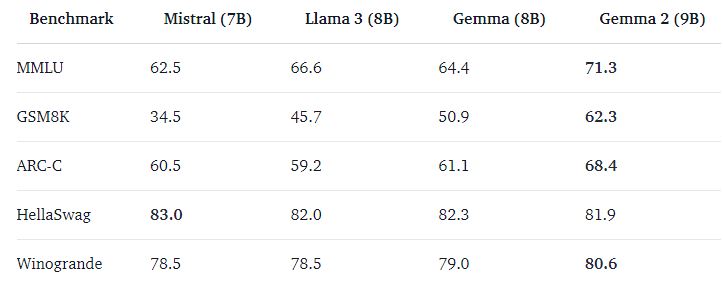
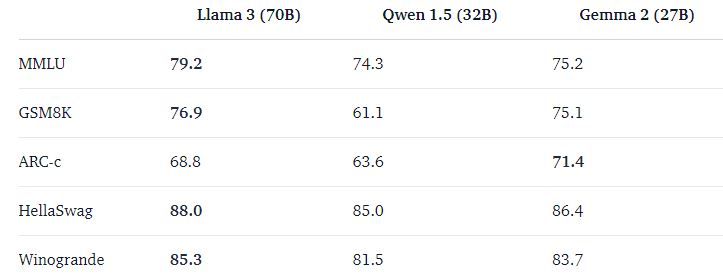
مدلهای جما چقدر خوب هستند؟ در ادامه، مقایسهای از عملکرد این مدلها با سایر مدلهای باز دیگر خواهیم دید
نتایج گزارش فنی
گزارش فنی جما ۲ عملکرد مدلهای زبانی بزرگ (باز) مختلف را بر اساس معیارهای ارزیابی جدول ردهبندی مدلهای زبانی بزرگ (باز) مقایسه میکند.
این مقایسهها به ما کمک میکند تا بفهمیم مدلهای جما در مقایسه با سایر مدلهای موجود چگونه عمل میکنند و نقاط قوت و ضعف آنها را بهتر درک کنیم.
در همین خصوص جداولی مقایسهای تهیه دیده شده است که به شرح ذیل میباشد.
چطور از جما ۲ استفاده کنیم
مدلهای پایه هیچ قالب خاصی برای ورودی ندارند. مانند سایر مدلهای پایه، میتوان از آنها برای ادامه دادن یک دنباله ورودی با یک ادامه منطقی یا برای نتیجه گیری zero-shot/few-shot استفاده کرد. نسخههای دستورالعملی (Instruct) دارای ساختار مکالمه بسیار سادهای هستند:
<start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
LaMDA<end_of_turn>
<start_of_turn>model
LaMDA who? <end_of_turn><eos>این قالب باید دقیقاً تکرار شود.
قطعه کد زیر نحوه استفاده از gemma-2-9b-it با transformers را نشان میدهد. این مدل به حدود ۱۸ گیگابایت حافظه RAM نیاز دارد که در بسیاری از GPUهای مصرفی قابل اجراست. همین قطعه کد برای gemma-2-27b-it نیز کار میکند که با ۵۶ گیگابایت حافظه RAM، آن را به یک مدل بسیار جالب برای موارد استفاده تولیدی تبدیل میکند. مصرف حافظه را میتوان با بارگذاری در حالت ۸ بیتی یا ۴ بیتی بیشتر کاهش داد.
from transformers import pipeline
import torch
pipe = pipeline («text-generation»,
model= «google/gemma-2-9b-it»,
model_kwargs= {«torch_dtype»: torch. bfloat16},
device= «cuda»,)
messages = [{«role»: «user», «content»: «Who are you? Please, answer in pirate-speak.»},]
outputs = pipe (messages,
max_new_tokens=256,
do_sample=False,)
assistant_response = outputs[0] [«generated_text»] [-1] [«content»]
print (assistant_response)
ادغام با Google Cloud
در حال حاضر گوگل مشغول اضافه کردن کانتینرهای جدید به GKE و Vertex AI است تا بتواند Gemma ۲ را به طور کارآمدتری اجرا نماید.
تنظیم دقیق با TRL
آموزش مدلهای زبانی بزرگ (LLM) میتواند از نظر فنی و محاسباتی چالشبرانگیز باشد. در این بخش، ما به ابزارهای موجود در اکوسیستم Hugging Face نگاه میکنیم که به ما امکان میدهند Gemma را به طور کارآمد روی GPUهای مصرفی آموزش دهیم.
در زیر، یک نمونه دستور برای تنظیم دقیق Gemma بر روی مجموعه دادههای گفتگوی OpenAssistant آورده شده است. از کوانتیزاسیون ۴ بیتی و QLoRA استفاده شده تا حافظه حفظ شود و تمام لایههای خطی بلوکهای اعلان را هدف قرار دهد. توجه داشته باشید که برخلاف ترنسفورمرهای متراکم، نباید لایههای MLP را هدف قرار دهیم، زیرا آنها اسپارس (کمتراکم) هستند و با PEFT خوب تعامل نمیکنند.
ابتدا، نسخه TRL را نصب کنید و مخزن را کلون کنید تا به اسکریپت آموزش دسترسی پیدا کنید.
این دستورات به شما امکان میدهند ابزارهای لازم برای تنظیم دقیق مدل Gemma را نصب کرده و به کد مورد نیاز دسترسی پیدا کنید. در ادامه، میتوانید از این ابزارها برای بهبود عملکرد مدل بر اساس نیازهای خاص خود استفاده کنید.
pip install «transformers>=4.42. 3» –upgrade
pip install –upgrade bitsandbytes
pip install –ugprade peft
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trlسپس میتوانید اسکریپت را اجرا کنید:
# peft tuning; single GPU; https://wandb.ai/costa-huang/huggingface/runs/l1l53cst
python \
examples/scripts/sft. py \
–model_name google/gemma-2-27b \
–dataset_name OpenAssistant/oasst_top1_2023-08-25 \
–dataset_text_field= «text» \
–per_device_train_batch_size ۱ \
–per_device_eval_batch_size ۱ \
–gradient_accumulation_steps ۴ \
–learning_rate 2e-4 \
–report_to wandb \
–bf16 \
–max_seq_length ۱۰۲۴ \
–lora_r ۱۶ –lora_alpha ۳۲ \
–lora_target_modules q_proj k_proj v_proj o_proj \
–load_in_4bit \
–use_peft \
–attn_implementation eager \
–logging_steps=10 \
–gradient_checkpointing \
–output_dir models/gemma2در صورتی که پردازندههای گرافیکی قویتری دارید، میتوانید آموزش را با DeepSpeed و ZeRO Stage ۳ اجرا کنید:
accelerate launch –config_file=examples/accelerate_configs/deepspeed_zero3. yaml \
examples/scripts/sft. py \
–model_name google/gemma-2-27b \
–dataset_name OpenAssistant/oasst_top1_2023-08-25 \
–dataset_text_field= «text» \
–per_device_train_batch_size ۱ \
–per_device_eval_batch_size ۱ \
–gradient_accumulation_steps ۴ \
–learning_rate 2e-5 \
–report_to wandb \
–bf16 \
–max_seq_length ۱۰۲۴ \
–attn_implementation eager \
–logging_steps=10 \
–gradient_checkpointing \
–output_dir models/gemma2راهنمای استفاده
شما میتوانید Gemma ۲ را روی Hugging Face’s Inference Endpoints با استفاده از Text Generation Inference به عنوان بکاند مستقر کنید. Text Generation Inference یک کانتینر نتیجه گیری آماده برای تولید است که توسط Hugging Face توسعه داده شده تا استقرار مدلهای زبانی بزرگ را آسان کند. این ابزار دارای ویژگیهایی مانند دستهبندی مداوم، پخش جریانی توکنها، موازیسازی تنسور برای نتیجه گیری سریع روی چندین GPU، و ثبت و ردیابی آماده برای تولید است.
برای استقرار یک مدل Gemma ۲، به صفحه مدل بروید و روی ابزارک Deploy -> Inference Endpoints کلیک کنید. Inference Endpoints از Messages API سازگار با OpenAI پشتیبانی میکند که به شما امکان میدهد با تغییر ساده URL، از یک مدل بسته به یک مدل باز تغییر حالت دهید.
به زبان سادهتر:
- ۱. Gemma ۲ را میتوان روی سرویسهای Hugging Face اجرا کرد.
- ۲. برای این کار، از یک ابزار به نام Text Generation Inference استفاده میشود.
- ۳. این ابزار امکانات مفیدی مثل پردازش سریع و همزمان چندین درخواست را فراهم میکند.
- ۴. برای استفاده از Gemma ۲، کافیست به صفحه مدل بروید و گزینه استقرار را انتخاب کنید.
- ۵. میتوانید به راحتی از مدلهای بسته به Gemma ۲ تغییر حالت دهید، که این کار فقط با عوض کردن آدرس URL ممکن میشود.
این قابلیتها به شما امکان میدهد از Gemma ۲ در پروژههای واقعی استفاده کنید، بدون اینکه نگران مسائل فنی پیچیده باشید.
from openai import OpenAI
# initialize the client but point it to TGI
client = OpenAI (base_url= «<ENDPOINT_URL>» + «/v۱/»، # replace with your endpoint url
api_key= «<HF_API_TOKEN>»، # replace with your token)
chat_completion = client. chat. completions. create (model= «tgi»,
messages= [{«role»: «user», «content»: «Why is open-source software important?»},]،
stream=True,
max_tokens=500)
# iterate and print stream
for message in chat_completion:
print (message. choices[0]. delta. content, end="") منابع اضافی
- ۱. مدلهای موجود در Hub: میتوانید مدلهای مختلف را در پلتفرم Hugging Face پیدا کنید.
- ۲. جدول ردهبندی مدلهای زبان بزرگ باز: این جدول عملکرد مدلهای مختلف را مقایسه میکند.
- ۳. نمایش گفتگو در Hugging Chat: میتوانید عملکرد مدل را در یک محیط چت آزمایش کنید.
- ۴. وبلاگ گوگل: برای اطلاعات بیشتر از طرف تیم گوگل.
- ۵. Google Notebook: به زودی در دسترس خواهد بود.
- ۶. مدل Vertex AI: این هم به زودی در دسترس خواهد بود.






