در پیش رو یک روش جدید در دنیای هوشمصنوعی خواهیم داشت که با استفاده از آن میشود چیزی را خلق کرد که هم به عنوان یک تصویر به نظر میرسد و هم زمانی که آن را پخش کنیم به عنوان یک صدا شنیده شود. امیدوارم در مسیر مطالعه کلمات موجب گیجی و عدم درک موضوع نشوند.
به عنوان مثال تصور کنید که در حال نگاه کردن به یک گل زیبا هستید و آنچه در روبرو چشمان شماست در درک شما یک تصویر زیبا را خلق میکند. اما اگر بخواهید شنونده صدای این گل باشید یا وجود ندارد و یا صدایی عجیب در انتظار شماست. اما روشی که در ارتباط با آن صحبت خواهیم کرد به ما این امکان را میدهد که تصاویری خلق کنیم که وقتی اقدام به پخش آن میکنیم صدایی زیبا و طبیعی نیز داشته باشند.
این اتفاق با استفاده از دو مدل ماشین لرنینگ صورت گرفته است. که یکی تولید کننده تصویر و دیگری تولید کننده صوت میباشد. این دو مدل در یک سطح مشترک کار خود را انجام میدهند و در زمان خلق یک نمونه جدید، هر دو مدل با هم اقدام کرده تا نمونه، یک تصویر و یک شکل صوتی قابل قبول باشد.
در نهایت امکان تبدیل به فرمت صوتی و یا رنگی کردن تصاویر برای جلوه بهتر به کمک هوش مصنوعی وجود دارد.
خلاصه آشنایی با هوشمصنوعی صداساز
طیف نگارهها نمایشی ۲بعدی از صدا هستند که بسیار با تصاویری که در جهان بینایی ما وجود دارند متفاوت به نظر میرسند و همینطور تصاویر طبیعی وقتی به عنوان یک طیف نگاره پخش شوند، صداهای غیر طبیعی تولید میکنند. این مقاله و این روش قصد دارد بگوید که امکان سنتز طیف نگارههایی وجود دارد که هم شبیه تصاویر طبیعی به نظر برسند و هم شبیه صداهای طبیعی به گوش برسند. تیم محققین برای این حاصل و این طیف نگارههای خلق شده عبارت «تصاویری که صدا دارند» را انتخاب کردهاند که به نظر انتخاب به جایی است.
رویکرد محققین هوشمصنوعی، ساده و بدون نیاز به آموزش قبلی به نظر میرسد به نحوی که از مدلهای پیش آموزش دیده متن به تصویر و متن به طیف نگاره استفاده میکنند که در یک فضای مشترک عمل میکنند. در طول فرایند معکوس، با استفاده از برآوردهای نویز، هم از مدل صوتی و هم از مدل تصویری به طور موازی، نویز را از نمونهها حذف میکنند.
در نتیجه نمونهای به دست میآید که هم تحت توزیع تصاویر و هم تحت توزیع صداها احتمال بالایی دارد. از طریق ارزیابیهای کمی و مطالعات ادراکی، نتیجه بر این شد که این روش میتواند با موفقیت طیف نگارههایی تولید کند که با صوت همسو بوده و در عین حال در ظاهر بصری هم میتواند تصویر مورد نظر را به خود بگیرد.
همانطور که در فایل زیر مشاهده میکنید از مدلهای انتشاری استفاده شده که شبیه تصویر هستند اما میتوانند به عنوان صدا نیز پخش شوند.
همچنین نمونه های دیگری نیز به کمک این هوشمصنوعی ساخته شده است که آنها را میتوانید ببینید.
نمونه های رنگی شده
نمونههای سیاهوسفید
روش اجرا

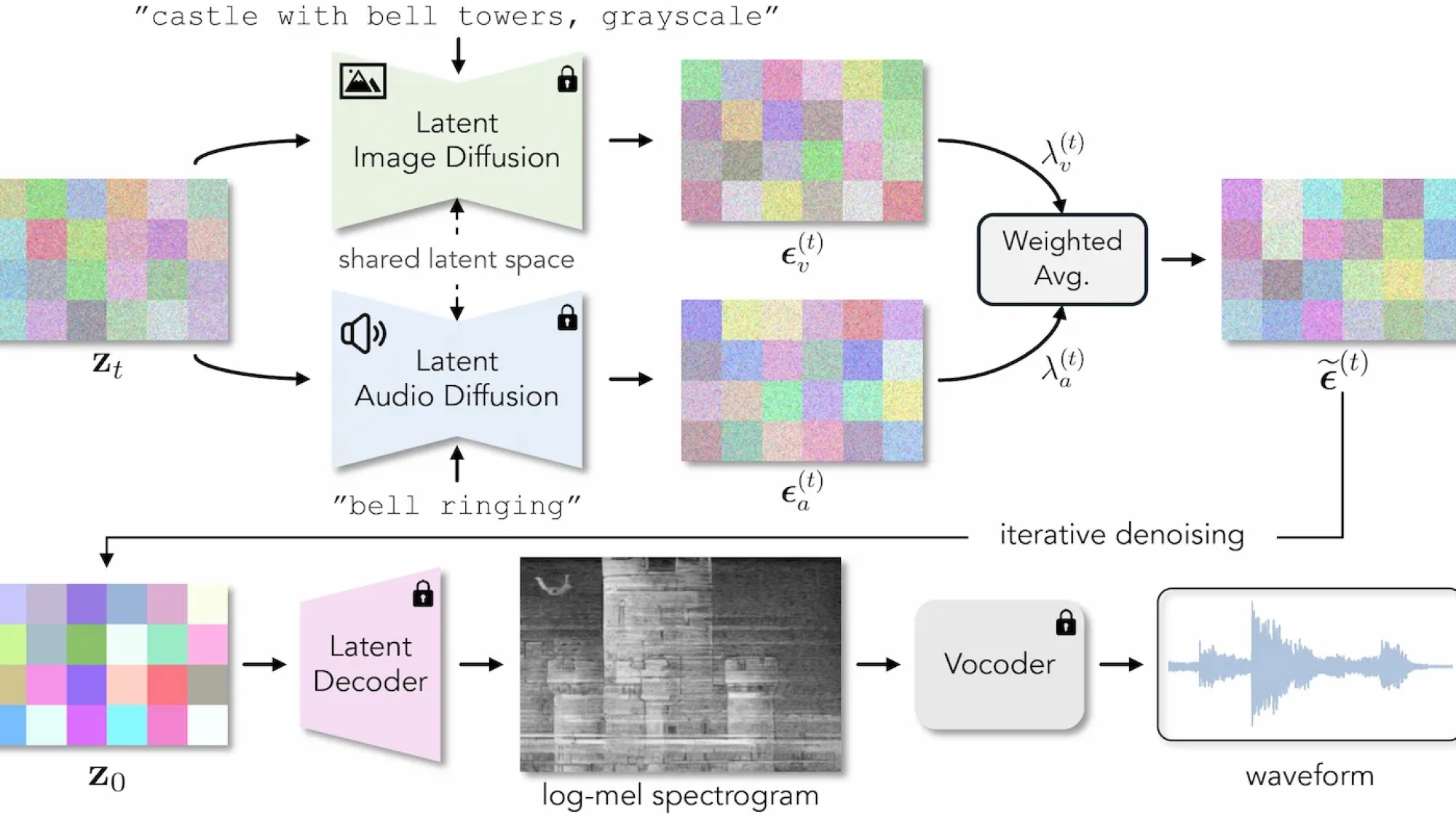
در خصوص روش اجرا این فرآیند تیم تحقیقات اینطور بیان میکند که در ابتدا مسئله را به عنوان یک مشکل ترکیب چند مودال (تصویر و صدا) مطرح میکنند. و هدف این است که نمونهای به دست بیاید که هم تحت توزیع تصاویر و هم تحت توزیع طیف نگارهها محتمل باشد.
در مرحله بعد به طور همزمان از یک مدل پخش تصویر (image diffusion model) و یک مدل پخش صوتی (audio diffusion model) استفاده میشود تا نویزها را از نمونهها حذف نمایند.
در قدم بعد یک نمونه نویزی (Latent) داریم که از هر دو مدل چه تصویر و چه صوت یک برآورد/تخمین از نویز موجود در این نمونه را محاسبه میکنیم.
در ادامه یک برآورد/تخمین ترکیبی از نویز را از طریق میانگین وزنی از دو تخمین قبلی به دست میآوریم.
حالا با استفاده از تخمین ترکیبی، نویز را از نمونه نویزی اولیه کم میکنیم تا به یک نمونه اصطلاحا تمیز (clean latent) دست پیدا کنیم.
در نهایت نمونه تمیز ما به یک طیف نگاره تبدیل میشود و با استفاده از یک مدل وکدر (vocoder) از پیش آموزش دیده آن را به موج صوتی یا همان ویوفرم معروف تبدیل میکنیم.
این روش بدون نیاز به آموزش یا fine-tuning خاصی قابل اجرا است، چون فقط در مرحله inference تغییر ایجاد میکند
برخی موزیسینها تصاویری را در طیف نگارههای خود قرار دادهاند. که از طریق لینکهای زیر میتوانید آنها را مشاهده کنید. البته که سبکهای موسیقی که امکان استفاده از این روش را دارند زیاد متعارف به نظر نمیرسند. در نهایت امیدوارم از این مقاله هوشمصنوعی استفاده لازم را برده باشید.
همچنین بررسی این لینک در گیت هاب را به شما پیشنهاد میکنم.
در خصوص فرایند های اجرا اگر تمایل به داشتن اطلاعات بیشتری دارید میتوانید از این لینک استفاده کنید.
در این خصوص یک سایت به صورت تخصصی تر وجود دارد که این لینک شما را به آن سایت منتقل میکند.
اگر به AI علاقهمند هستید میتوانید صفحات «اخبار هوشمصنوعی» و «مقالات هوشمصنوعی» را دنبال کنید.
افکارتان را باما در میان بگذارید